Blog Full Notice
back to main page
C++ 기본 개념 정리 네이버 블로그
motivation: 네이버 블로그
#c++ 기본 개념 정리 : 네이버 블로그
c++ 애매한 개념이 너무 많아서 내 입장에서 애매한 기본 개념을 정리하려고 한다.
책은 fundamentals of C++ programming, 2018, Richard L. Haleterman이다.
Ch.1. The context of software development
프로그래머는 software development process를 향상시키기 위한 다양한 tool들을 사용한다. editor, preprocessor, compiler, linker, debugger, profiler가 있다. preprocessor는 compiler가 code를 process 시키기 전 라이브러리를 include시키는 과정(#include). compiler는 object code로 라이브러리와 editor에서 편집한 소스 코드를 합친다. linker는 compile된 라이브러리 object code를 source code와 연결시키는 작업을 함. 그러면 실행 가능한 프로그램이 작성 됨. profiler는 프로그램 실행에 관한 총계를 수집하여, 개발자로 하여줌 성능향상을 하도록 프로그램을 조정할 수 있게 해준다. profiler는 모든 코드가 실제로 어딘가에서 실행되고 있는지 시험해 볼 수 있는데, 이를 coverage 과정이라고 한다. 즉 profiling은 프로그램 특정 부분을 향상시켜 프로그램이 더 빠르게 실행될 수 있도록 한다.
Ch.3. Values and variables
운영체제에 따라서 '\n'이 carrage return(왼쪽으로 가는 것), line feed(한줄 밑으로 가는 것)으로 나뉜다. windows의 경우 CR LF, linux의 경우 LF가 된다. 그러나 c++에서는 c++ standard에 의해 동일하게 나오도록 보장된다.
한번 변수가 선언되면 재선언될 수 없다. 선언되지 않은 변수 쓰면 에러.
16진수 표현 방식: OxA9 = 169(숫자 앞에 Ox을 붙임)
8진수 표현 방식: 0110 = 72(숫자 앞에 0을 붙임)
superscript 표현 방식: 6.023 * 10^23 = 6.023e23
float = 10.2F, unsinged long long = 10.43uLL, 특히 long 값은 l이 1과 혼동될 수 있기 때문에 대문자로 쓰는 것이 일반적.
자료형의 경우 운영체제에 따라 몇byte가 최대인지 바뀜. 그러나 큰 값이 작은 값보다 최대값이 크거나 같은 것은 확실함.
enumerated type: enum Color {yellow,red, orange}; Color myColor; myColor = orange; 이런 스타일의 enumerated type definition은 unscoped enumeration이라고 불림.
unscoped enumeration이 안좋은 이유는 enum Color {yellow,red, orange}; enum Fruit {banana, orange};를 하게 되면 duplicate enumeration values in different type를 가지는데 이게 오류를 만듬. 따라서 이를 해결하기 위해 scoped enumeration 방식으로 정의되는 enumeration class라는 개념이 나왔음. enumeration class는 enum class Shade { Dark, Dim, Light}; Shade color = Shade::Light; 이런 식으로 ::operator를 사용해서 compiler가 겹치는 두가지 값을 구별할 수 있도록 해준다.
auto x;와 같이 선언만 해주면 오류남. 정의가 같이 되어야 함.
Ch.4. Expressions and Arithemetic
double dominates int-truncation: / operator의 오른쪽이나 왼쪽 하나만 double이면 truncation 안 일어남.
4.6 Errors and warnings
error는 3가지로 이루어져있다. 1) compile-time error 2) run-time error 3) logic error. 1) compile-time error 는 syntax error와 link error로 이루어져 있다. 2) run-time error는 invalid memory access(int인데 사용자가 double형 입력하는것), memory leak(메모리 다 쓰고 반납 안하면 program crash == run-time error)가 있다. 즉 run-time error는 실행은 잘 되는데 내가 원하는 것이 아니라는 오류가 나오는 것이다. 이때 프로그램이 crash 되었다고 한다. run time error의 예는 divide by zero가 있다. logic error은 wrong formula/output, division by zero가 있다. logic error의 특징은 포로그램은 error를 가지고 있지만, compiler나 run-time system이 detect하지 못하는 error다. 즉 잘못된 결과값을 출력하는 프로그램이다. logic error의 예로는 프로그래머가 원래 dividend/divisor라고 써야 하는데 divisor/dividend라고 잘못 쓰는 것이다.
초보자는 compile error를 초반에 많이 한다. 그러나 숙달이 될수록 logic error가 늘어난다.
bug == compiler detection에서 벗어나는 error들인 run-time error와 logic error를 의미한다.
Compiler Warning은 compiler가 C++ 언어 규칙을 지키지 않은 경우 주는 notification이다. 예를 들어 uninitialized object라던지, Narrowing conversion이라던지(double to int). 이럴때는 static_cast<int>를 쓰면 해결되긴 한다.
unsigned tiny는 5bit만 사용하는 (0-31) 자료형이다.
bitwise operator에는 <<와 >>가 있다. <<는 shift left다. >>는 shift right다. 5 << 2 하면 20된다.
bitwise operator는 keyboard 동시에 누르는거에 활용될 수 있다.
c++에서 modulo operator는, quotient가 0을 중심으로 remainder가 형성이 된다. 이게 무슨 말이냐면 remainder-quotient theorem에서, n = dq+r인데, for positive integer d, there is a unique integer q and r s.t. 0 <= r < d 이지 않은가. python의 경우 이 theorem이 적용이 되는데, c++의 경우 q가 0 쪽으로 형성이 된다. 즉 q가 음수이면 r이 음수가 된다.
Ch.5. Conditional Execution
operator precedence: 1. scope resolution 2. a++, a--, a[], static_cast<int>, reinterpret_cast<int *>, ., -> 3.(right to left associativity) --a ++a, &p *p, -a +a, !,~, new delete, (int), sizeof 4. * / % 5. + - 6. >> << 7. < <= > >= 8. == != 9. & 10. ^ 11. | 12. && 13. || 14. (right to left associativity) ?: assignment(=) compound assignments >>= |= +=
a++, a[], *a, ++a에서 right to left associativity보다 우선순위가 높고, a가 왼쪽에서 나오면 left to right associativity 이고, ++a 처럼 a가 오른쪽에서 나오면 right to left associativity 이다.
보통 left to right associativity가 right to left associativity보다 우선순위가 높다.
복잡한 구문의 operator precedence를 판단할 때에는 clockwise/Spiral Rule을 사용한다. 자세한 내용은 링크 참조.(https://stackoverflow.com/questions/24685173/how-are-complex-declarations-parsed-in-terms-of-precedence-and-associativity) (https://c-faq.com/decl/spiral.anderson.html)
Ch.6. Iteration
#include <iomanip>: std::cout << std::setw(10) << x << '\n'; -> 오른쪽 정렬
#include <locale>: std::cout.imbue(std::locale("")); std::cout << std::setw(13) << x; -> 3자리마다 컴마 생김.
break,continue는 for/while loop에 적용 가능. break는 loop을 바로 나감. continue는 for loop의 경우에는 modification 부분에 가고 while의 경우에는 조건 검사하는 곳으로 감. 그러나 break나 continue는 if-else문으로 대체가 가능하긴 하다.
goto end;하면, int main() 함수 안에 end:라고 특정 위치를 지정해 주어야 함.
Ch.7. Other Conditional and Iterative Statements
switch statement는
switch (value) {
case 1:
std::cout << "1";
break;
case 2:
std::cout << "2";
break;
default:
std::cout << "3";
}
형태로 표현 가능하다.
for(;;) 형태로도 사용 가능하다. 이때 초기화는 loop 밖에서 해줘야 하고, 조건의 경우 break나 goto를 반드시 사용해야 하고, modification은 loop 내부에서 해줘야 한다.
Ch.8. Using functions
#include <cmath>: parameter, return값 다 double인 함수: sqrt,exp,log,log10,cos, pow(2,2),fabs
#include <algorithm>: std::max(value1,value2), std::min(value1,value2)
#include <ctime>: // elapsed time 구하는 방법
clock_t timeNowInMilliSec1 = clock();
std::cin >> a;
clock_t timeNowInMilliSec2 = clock(); // (clock_t = unsigned long)
double elapsedTime = static_cast<double>(timeNowInMilliSec2 - timeNowInMilliSec1) / CLOCKS_PER_SEC(1000); //elapsed time
#include <cctype> parameter, return값 모두 int인 함수: toupper, tolower, isupper, islower, isalpha, isdigit
#include <cstdlib>: // random number generation
srand(static_cast<unsigned>(time(0)));
int r = rand() % 100 + 1; // 1-100 범위의 정수.
Ch.9. Writing functions
pass by value: 서로 복사하는 변수 두개의 주소값이 다르다. 따라서 복사 이후 변수들은 서로 연결되지 않는다.
pass by reference: 서로 복사하는 변수 두개의 주소값이 같아진다.
함수 선언할 때 int func(int);형태로 선언도 된다. int func(int, int y, int );형태로도 선언이 가능하다.
또한 함수 선언할 때 int func(int, int y, int ); 이렇게 하고, 정의할 때 다시 int func(int a, int b, int c);할 수 있다.
이게 무슨 의미를 가지냐면 선언 할 때에는 함수의 signature만 중요하다는 것이다. 또한 함수의 선언에서 formal parameter는 적지 않아도 된다는 뜻이다. 함수의 정의에서만 formal parameter를 반드시 적어줘야 하는 것이다.
따라서 함수의 선언과 정의를 동시에 할 때에는 반드시 formal parameter를 적어줘야 하는 것이다.
Ch.10. Managing functions and data
전역변수 x와 지역변수 x가 같이 있을 때 전역변수 x에 접근하기 위해 ::x-- (::)를 사용하게 된다.
'내부 링크가 있는 변수를 static 변수라고 한다. static 변수는 변수가 정의된 소스 파일 내에서 어디서나 접근할 수 있지만, 소스 파일 외부에서는 참조할 수 없다. 외부 링크가 있는 변수를 extern 변수라고 한다. extern 변수는 정의된 소스 파일과 다른 소스 파일 모두에서 접근할 수 있다.' extern 키워드는 두 가지 다른 의미가 있다. 어떤 상황에서는 extern 키워드가 '외부 링크가 있는 변수를 의미' 하고 다른 상황에서는 '다른 어딘가에서 정의된 변수에 대한 전방 선언'을 의미한다. 출처: https://boycoding.tistory.com/167 [소년코딩:티스토리]
1) extern const int a = 1; in ex.h, extern const int a = 1; in main.cpp, 이때 main.cpp에 있는 extern은 전방선언을 위한 extern이다. 전방선언(forward declaration)이란 맨 처음에 전방선언 하면 그 다음부터는 접근하고 쓸 수 있게 된다는 것이다. 2) ex.h에 있는 extern은 외부 링크가 있는 변수를 의미한다.
static 변수들은 compile-time에 다 결정 됨. 특히 static 변수들은 global 변수와 마찬가지로 초기화 안해도 0으로 설정됨. 그 이유는 프로그램의 일반적 프로그램 메모리 segment의 구조를 통해 알 수 있다. 프로그램 메모리 segment의 구조는 1. code/text segment(.code) 2. Initialized data segment(.data) 3. uninitialized data segment(.bss) 4. heap, 5. stack 순으로 stack이 큰 주소값을 가지고, code segment가 가장 작은 주소값을 갖는다. 여기서 중요한 것은 2. initialized data segment, 주로 data segment라고 불리는 곳이다. 여기는 프로그램의 가상 주소 공간의 일부분으로 초기화된 전역변수와 초기화된 static 전역변수를 포함한다. 3. uninitialized data segment(.bss)는 0으로 모두 초기화가 된다. 이렇게 구분되는 이유는 code segment는 ROM에 저장하고, data segment는 ROM에 저장하고 변수를 사용하기 위해서 RAM에 변수를 저장을 하고, uninitialized data segment(BSS segment)는 굳이 ROM에 저장할 필요 없이 0으로 초기화되어 RAM에 저앙하여 바로 쓰이게 할 수 있다.(data segment 출처: https://blog.naver.com/PostView.nhn?blogId=cjsksk3113&logNo=222270185816)
전역변수의 경우에만 extern을 안써도 묵시적으로 extern이 사용이 된 것처럼 파일 밖에서도 사용이 가능하다. main 함수 내에서는 전역변수로 쓰려면 static이나 extern을 반드시 써야 한다.
header 파일에 있는 전역변수를 사용하고자 할 때 extern을 사용해야 한다.
main 함수 내에static int a;를 사용하게 되면 이 파일 내에서만 사용할 수 있는 전역변수가 만들어진다.
static int count(int n) {} 도 사용 가능함. 근데 이거에 대한 내용은 책에 별로 없는듯.
formal parameter: 함수 정의할 때 들어가는 parameter. actual parameter: 함수 호출할 때 들어가는 parameter (int foo(int x) 에서 x는 formal parameter, foo(x) 호출할 때 x는 actual parameter.
int& r = x;(int x = 5;) 자료형 뒤에 나오는 &기호는 declaration, that r references x.(r aliases(별칭) x)
& == address of operator (*p = &x;)
reference 는 선언만 할 수 없음. 정의가 같이 되어야 함. 또한 nullptr 대입 불가능.
function overloading
overloaded function (중복정의된 함수): 하나의 프로그램 안에 2개 이상의 함수가 같은 이름을 가지고 있을 떄, 중복정의된 함수라고 한다. 2개 이상의 함수가 같은 이름을 가지고 있을 때 함수는 signiture에 의해 구별된다. function signiture는 함수 이름과 파라미터 리스트로 구성된다. 파라미터 리스트에는 formal parameter의 종류,숫자,순서만 상관있고, 이름은 상관없다. 만약 함수의 이름이 갖고, formal parameter의 종류, 숫자, 순서가 다르다면 function signature는 다르다고 할 수 있다.
함수를 선언만 할 때에는 함수의 formal parameter의 자료형만 적어주면 된다. 즉 int foo(int,int,double);만 해도 된다. 또한 함수의 선언할 때 썼던 formal parameter 이름과 함수 정의 부분의 formal parameter 이름이 달라도 된다. 아마 함수의 signature가 달라서 그런 것 같다.
default argument/parameter: default parameter와 non-default parameter들을 섞을 수 있다. 그러나 이 둘을 섞으려면 parameter list에 있는 모든 default parameter들은 non-default parameter 후에 나타나야 한다. 예를 들어 int foo(int n = 10, int m) {} 은 illegal이다. default parameter는 항상 뒤에서부터 시작해야 한다.
default argument와 function overloading은 같이 쓰지 않는것이 좋다. void f(){}; 와 void f(int n=0){};은 f();를 호출했을 때 에러가 난다. 에러가 나는 이유는 컴파일러가 어떤 함수를 호출할지 모르기 때문이다. void f(int m){}; 와 void f(int n=0){}; 는 function signature가 완벽히 동일하기 때문에 에러가 난다.
formal parameter로 const keyword를 쓸 수 있을까? pointer나 reference는 가능하다. 즉 pass by pointer 또는 pass by reference는 const keyword를 formal paramter에 쓸 수 있는 반면, pass by value는 const keyword를 formal paramter에 쓸 수 없다. 그 이유는 다음과 같다. 만약 int foo(int i){}와 int foo(const int i){} 가 있다고 하자. 그리고 main 함수에서 foo(k);를 호출했다고 하자. 이때 compile error가 나타나는 이유는 어처피 main 함수의 k를 foo는 수정할 수 없다. 왜냐하면 pass by value이기 때문에 i는 k를 복사한거여서 별개의 변수이기 때문이다. 따라서 formal paramter가 const로 선언되었건 안 선언 되었건 그냥 차이가 없다. 따라서 compiler가 어떤 함수를 실행해야 되는지 모호하기 때문에 compile error가 나타나는 것으로 해석할 수 있다. 반면 reference/pointer의 경우 main 함수에 있는 k를 변경할 수 있다. 따라서 formal paramter에 const를 쓰고 안쓰고에 따라서 다른 version의 function이 만들어질 수 있다.
pointer
int *; declaration, that p is a pointer to an int.
* == unary * operator == pointer dereferencing operator (*p = 7;)
int *p = 5; c++에서 direct integer assignment to pointer를 허용 안함. 특별한 type cast를 써야함. p = reinterpret_cast<int *>(5)를 쓰면 주소 5에서 int pointer로 선언됨. p = reinterpret_cast<int *>(&객체) 형식으로 쓰게 되면 member변수 중 하나의 주소가 대입되는 듯. 이거는 추측.
int *p; 에서 p를 unitnitialized pointer/wild pointer라고 함. 이 wild pointer를 p라고 했을 때 쓰레기 값을 가지고 있는다. 이때 *p = 500을 하게 되면 error가 발생하게 된다. 그 이유는 wild pointer는 쓰레기값을 가지고 있고, 이 wild pointer는 특정 주소를 가지고 있는 변수이므로 나도 모르는 주소값에 500이라는 값을 가지도록 만드는 것이기 때문이다. 만약 실행 프로그램의 영역에 그 포인터 주소값이 있었다면 error가 나지 않고, 잘 동작하긴 하겠지만, compile된 머신 언어 instruction를, 또는 다른 변수를 override할 가능성이 있다. 그러면 프로그램이 그 변수를 접근할 때 까지 error를 발견할 수 없다. 만약 이때 error가 발생하더라도 error가 발생한 부분은 error를 일으킨 부분의 부근(vicinity)에 없어서 고치기가 쉽지 않다. 따라서 p = nullptr를 쓴다. 이거는 address 0를 포인터에 저장한다. 이 주소는 모든 실행되는 프로그램의 범위 밖에 있다. 따라서 nullptr를 배정한 포인터를 dereference 하게 되면 runtime error가 발생한다. C++11 이전에는 nullptr라는 것을 명시하기 위해 p = 0을 썼는데, nullptr과 0의 차이점은 nullptr은 오직 포인터형 변수에만 대입되고, 다른 자료형에 nullptr를 대입하면 compile error가 뜬다. 따라서 nullptr를 쓰는 것이 좋다.
pass by reference via pointers인데, double pointer로 swap함수를 구현하면 어떻게 될까?
void swap(int **a, int **b) {
int *temp = *a;
// 이 코드의 오류: int *temp를 써야 함. int**temp를 하게 되면 wild pointer가 됨. 그래서 오류. int *temp = *a를 써야 함.
*a = *b;
*b = *temp;
}
int main() {
int A=5,B=6;
int *pA = &A, *pB = &B;
swap(&pA, &pB);
}
하면 원래 pA -> 5, pB -> 6 되고,
a -> pA -> 5, b -> pB -> 6 되고,
a -> pB -> 6, b -> pA -> 5가 된다.
따라서 A,B값은 바뀌지 않는다. 단 pA, pB값만 바뀐다. 왜 A,B 값은 바뀌지 않냐면 변수의 메모리 주소는 절대 변하지 않기 때문이다.
모든 변수의 메모리 주소는 절대 변하지 않는다. 예를 들어 int a = 0;이라고 하면 a의 &a(주소)는 항상 a를 의미한다. 즉 변수란 특정 메모리주소를 의미한다고 할 수 있다.
즉 변수의 본질은 메모리 주소에 있다.
그러나 우리가 사용하는 변수들은 메모리 주소를 사용하는 것이 아니라 그 메모리 주소가 가지는 값을 접근한다. 포인터 변수도 마찬가지다.
따라서 포인터도 변수고, 이 변수는 어떤 메모리 주소를 갖는 특별한 변수다. 따라서 이 변수도 본질은 이 변수값의 메모리 주소에 있다.
따라서 어떤 변수의 값을 swap 하고자 할 때 그 변수의 메모리주소를 dereference 시키고 그 값을 바꾸면 특정 변수가 바뀌게 되는 것이다.
higher-order function: 1)parameter로 함수를 갖는 함수 또는 2)함수를 return하는 함수.
하나의 함수는 하나의 동작밖에 못한다. 그러나 어떤 함수가 상황에 따라 다른 동작을 할 수 있도록 하면 되지 않을까?
c++는 higher-order function을 function pointer로 달성한다.
모든 함수는 각각의 메모리 주소가 있다.
pointer to function은 특정 함수의 compile된 machine code의 주소를 가지고 있다.
int add(int x, int y) return x+y;
int evaluate(int (*f)(int, int), int x, int y) return f(x,y);
일때 함수 호출은 evaluate(&add, 2,3);형식으로 해야 한다. 즉 higher order function에서 인수가 함수인 부분의 actual parameter는 higher order function의 정의에 적혀진것과 같은 함수의 원형(prototype/signature)과 동일한 함수(callback function)의 주소를 적는다.
주의할 점은 int evaluate(int *f(int,int)) {...} 이렇게 쓰면 안된다는 것. 이것은 evaluate((int *) f(int,int))가 될 수 있음. (참고: https://stackoverflow.com/a/34474431/1943679, 폰 노이만 기계는 자료형을 구분하지 못한다. assembly어로 구분해야 함. PC counter로 assembly어 명령어로 구분됨.)
int (*func)(int,int); func = add; func(2,7); 이렇게도 사용 가능.
Ch.11. Sequences
Nonempty sequence == linear ordering이다. linear ordering에서는 첫번째 element에서 마지막 element까지 successor element를 방문할 수 있다.
Vector
vector is an object that manages a block of memory, whichis a collection of homogenous values. we can access the values it contains by their position within the block of memeory managed by the vector.
#include <vector> 반드시 추가
using std::vector; 하면 vector<int>만 사용 가능
using
std::vector<int> vec; 으로 선언 가능. //template이기 때문에 type 지정해 주어야 함.
std::vector<int> vec(10); 으로 size가 10개인 vector 선언 가능
std::vector<int> vec(10,8); 으로 8을 10개 가진 vector 선언 가능
std::vector<int> vec{10, 20, 30, 40, 50}; 으로 각각의 element를 개별로 정의할 수 있다. (C++11 이상)
// (parenthesis), {curly braces}, [brackets], curly braces안에 있는 element들은 vector initializer list 안에 구성됨.
vec[2] 수정, 접근 가능.
vector의 허용된 index 이상을 접근하게 되면 undefined behavior가 된다. C++ language standard는 undefined behavior를 프로그램 행동이 명시되어있지 않을때 사용한다. 즉 compiler writer들이 맘대로 작성해도 되는 부분이다. 종종 running program은 undefined behavior를 겪게 되는데 이때 crash되거나 가끔씩은 문제가 나타나지 않고 정확하게 행동될 것이다. 따라서 undefined behavior는 system dependent하고 compiler dependent하다. 어떤 프로그램에서는 out-of-bounds access가 logic error로 본다면, 이것은 unpredictable behavior이고, 이 unpredictable behavior는 incorrect behavior다.
그렇지만 out-of-bounds access는 vector 밖의 메모리에 접근하니깐 대부분의 OS에서는 프로그램을 멈추고 error 메세지를 비춘다.
vec[x]에 int만 가능.
for(int n : vec) {...} 도 가능. // 범위 기반 for loop이라고 함. range-based loop statement
for (double &n : vec) {...} 형태로 vector값 변경도 가능.
vector의 여러 method들.
vec.push_back(10),pop_back(), size(), empty(), clear();
vec.operator[](2) == vec[2] == vec.at(2) (vector의 out-of-bound access를 방지하기 위한 추가 method, 따라서 index bounds checking을 지원한다. -> out-of-bound access 하면 run-time error 발생)
void F(const std::vector<int>& vec) {for (auto &elem : vec) {...}} 에서 formal parameter에 copy by pass-by-reference로 할 수 있다.
multidimensional vector: std::vector<std::vector<int>> vec(2, std::vector<int>(3));
vec[0][0] = i; vec[0][1] = i; vec[0][2] = i;
vec[1][0] = i; vec[1][1] = i; vec[1][2] = i;
std::vector<std::vector<int>> vec{ {i, i, i} , {i, i, i} };
multidimentsional vector manipulation: std::vector<std::vector<int>> vec(2, std::vector<int>(3));
using Matrix = std::vector<std::vector<double>>하면 void print(Matrix m){} == void print(std::vector<std::vector<double>> m){} 과 같은 의미가 된다.
Arrays
array도 name과 homogenous value가 있고 value는 block of memory로 위치 접근 가능. global 또는 local variable임. 그러나 객체는 아님. 또한 vector와 달리 C/C++의 core에서 만들어져서(?) #include 전처리기 사용 안해도 됨.
static array
int arr[10]; 으로 선언 가능. 10 개의 정수로 이루어진 배열.
int arr[x];에서 x는 실행시간에 정의될 수 없다.
int arr[] = { 0, 1, 2, 3}; {}-initializer list로 compiler가 element의 개수를 셀 수 있어서 bracket에 숫자를 쓰지 않아도 됨.
array를 initializer list{...}로 초기화하면 default value로 0 이 들어감. 예를 들어 int arr[10] = { 0, 1, 2, 3}; 또는 int arr[10] = {};을 하게 되면 default value가 0이 됨. (char형 array도 '\0' == 0이 들어감)
단 int arr[10];을 하게 되면 배열에는 쓰레기 값이 들어가게 됨. 그 이유는 어떤 모든 함수의 지역변수로 선언되고 초기화를 안하면 쓰레기 값이 들어감. 그러나 전역변수(static/global) 또는 일부만 초기화한 배열을 선언했을 경우(위의 예- int arr[10] = { 0, 1, 2, 3}) 초기화되지 않은 배열의 index에는 0값이 들어감.
배열의 size 알아내는 방법: sizeof(arr)/sizeof(int)하면 됨. 사실은 없음.
따라서 배열을 formal parameter로 가지는 함수는 배열의 size도 formal parameter로 받아야 함.
arr+i+1 == arr[i+1]
int* p = &a[0];
int* p = a;
*p++와 (*p)++는 다르다. ++가 *보다 우선순위가 높음.
void print(int a[], int n) == void print(int *a, int n)
Dynamic arrays
static array의 size는 compile time에 결정됨. 따라서 flexibly-sized array인 동적 배열은 run-time에 결정됨.
만약 쓸 수 있는 가장 최대의 메모리를 사용하고자 한다면, 충분한 RAM이 없을 것이고, OS가 virtual memory를 만들게 된다. virtual memory는 그러나 프로그램의 속도를 굉장히 줄인다. 왜냐하면 running program의 memory 일정 부분을 disk drive로 부터 실어 나르기 때문이다. 따라서 자원을 현명하게 쓰는것이 좋다. (heap이 stack보다 큼)
double *ptr = new double[size];
delete [] ptr;
array를 복사하는 방법
int a[10], b[10]; ...; b = a; 는 compile error가 남. static array는 const pointer처럼 작동하기 때문에, 재배정할 수 없음. 따라서 constant pointer인 b는 assignment operator인 = 왼쪽에 올 수 없다. b가 가르키는 곳은 lifetime동안 평생 그것을 가르켜야 한다.
int a[10], *b; ...; b = a; 는 b가 const가 아닌 경우다. 이 경우는 합법인가? 합법이다. 그러나 이 코드에는 어떤 문제가 있을까? 이 코드는 b는 a의 copy가 아니다. b aliases a이다. 따라서 a를 변경하면 b의 content가 바뀐다.
int a[10], *b; ...; b = new int[10]; for(;;){ b[i] = a[i] }; 이 경우 declare, allocate space for copy, copy the elements 형태로 진행되어 잘 copy가 된다. 나중에 delete [] b;를 해주면 된다.
따라서 array copy는 for(;;){ b[i] = a[i] }; 이게 중요하다고 할 수 있다. int *a = new int[10]; int *a = new int[10]; b = a;를 해버리게 되면 delete [] b;를 하게 되면 memory leak이 발생하게 된다.
memory leak: 재배정된 array가 원래 가르키고 있던 memory block은 copy를 하게 되면 더이상 실행 프로그램은 접근을 할 수 없다. 따라서 array copy의 경우 직접 배정을 하지 말고 원소들을 복사하는 형태로 구현해야 한다.
Multidimensional array
선언: int arr[2][3];
선언: int arr[][3];
선언: int arr[][3] = {{0,1,2},{3,4,5}}; 도 가능. 무조건 첫번째 array의 index만 생략 가능하다. 함수의 formal parameter도 마찬가지. (initializer list로 정의를 할 때 해당되는 얘기) 그 이유는 배열은 원소의 offset을 알기 위해 포인터로 변하는데, 이 offset을 계산하기 위해 arr[i][j][k]에서 nj,nk의 차원만 필요할 뿐 ni는 필요하지 않다. (nj == j의 차원,nk == k의 차원, arr[i][j][k]는 offset은 i*nj*nk + j*nk + k, 여기서 ni는 쓰이지 않음.) 출처: https://stackoverflow.com/a/8205191
arr[i] = *(arr + i)
arr[i][j] == (arr[i])[j] (left-right associativity) == *(*(arr + i) + j)
C string
C array가 cout 되는 이유는 c string은 끝에 '\0'- null 문자가 들어가있다고 한다. 그래서 이거를 문장의 끝으로 인식해서 처리한다고 한다.
char *word1 = "Howdy"; std::cout << word << '\n'; // 안전하다.
char word2[256] = "Howdy"; std::cout << word << '\n'; // 위에꺼보자 안전하지 않다.
왜냐하면 256자 이상의 char를 입력하면 buffer overflow가 일어난다. 이거는 심각한 logic error를 일으킬 수 있다.
std::cin에서 공백도 포함하는 방법:#include <cstudio> char word[10]; fgets(word, 10, stdin); std::cout << word; fgets는 standard C 함수. stdin은 C의 구조체, std::cin과 비슷한 구조체.
그러나 char *word; std::cin >> word; 하면 심각한 오류가 남(undefined behavior). std::cin에서 가져온 문자들을 저장할 buffer를 할당하지 않기 때문이라고 하는데, C를 공부해야 이해할 수 있을 것 같다.
C string method
int strlen(const char *s): '\0' 미포함 s 문자 길이
char* strcpy(char*s, const char *t): '\0' 포함 t를 s로 복사, 이때 s가 t를 다 가지고 있을 수 있도록 큰 buffer여야 함.
char* strncpy(char *s, const char *t, unsigned n): '\0' 포함 최대 n만큼 t를 s로 복사, 이때 s가 적어도 n이상의 buffer여야 함.
int strcmp(const char *s, const char *t): 사전 순으로 s가 t보다 먼저 있으면 -1, s가 t가 같으면 0, s가 t보다 뒤에 있으면 1.
int strncmp(const char*s, const char*t, int n): 맨 처음 n개 문자만 사전 순으로 s가 t보다 먼저 있으면 -1, s가 t가 같으면 0, s가 t보다 뒤에 있으면 1.
Command-line arguments
int main(int argc, char *argc[]) { for (int i = 0 ; i<argc;i++) std::cout << argv[i] << '\n';}
한 다음 command line에서 파일 이름이 example.cpp였다면 example qwer asdf zxcv라고 치면
example
qwer
asdf
zxcv
가 나온다. 즉 char *argc[]는 argc가 array of C string이라는 것을 의미한다. 따라서 argc[0]는 파일명 그 자체고 argc[1]은 qwer, argc[2]은 asdf, argc[3]은 zxcv임을 알 수 있다.
Ch.12. Sorting and searching - 생략.
Ch.13. Standard c++ classes
#include <string>: operator[] operator= operator+= at length size find substr empty clear append 등등(cplusplus 웹사이트 활용, 또한 visual studio . 찍어서 method 활용)
공백도 포함해서 cin하는 방법: std::getline(std::cin, str); (str type: std::string)
std::cout << x << y; 의 의미는 std::cout.operator<<(x).operator<<(y);이다. std::cin 도 마찬가지.
#include <fstream>
std::ifstream fsTemp;
std::string str;
fsTemp.open("practiceFile.txt")
if (fsTemp.good()) {
std::getline(fsTemp, str, ',') //<string>의 함수
}
std::cin은 문제가 발생할 수 있다. enter를 치면 LF가 남아있을 수 있기 때문이다. std::cin이 입력 받을 때 LF(enter 키)를 인식하지만 LF키를 사실 없애주지는 않는다. std::cin.unsetf(ios::skipws); 를 하게 되면 skip whitespace를 설정 해제하게 되어 char를 std::cin하는 경우 space(32)와 LF(10)를 모두 인식하고 buffer에 저장하게 된다. 따라서 나머지 std::cin 구문이 buffer 안에 있는 문자가 들어가 생략이 된다.
따라서 std::getline(std::cin, str); 하기 전에 무조건 std::cin을 썼으면 std::cin 후에 std::cin.ignore를 해야 한다. (https://cboard.cprogramming.com/cplusplus-programming/122401-how-do-i-allow-spaces-cin.html) 그래야 buffer 안에 있는 것들을 제거해줄 수 있기 때문이다.
Ch.14. Custom objects
encapsulation: 캡슐화 한다는 뜻. 캡슐화 한다는 것은 무슨 의미인가? 캡슐화란 정보 은닉이다.
encapsulation은 정보 은닉한다는 개념이다. 왜 어떤 정보를 client에게서 숨겨야 하는가? 복잡한 프로그램/시스템 에서는 객체의 내부에 무분별한 접근을 허용하면 재앙적이다. 그 이유는 서투른 프로그래머의 한가지 변경은 전체 시스템을 망가뜨릴 수 있기 때문이다. C++에서는 public과 private으로 field(data member)와 method들을 정의 할 수 있다.(member는 class 내의 변수와 함수를 의미. class 내의 변수를 data member, class 내의 함수를 member function이라고 함.)
public과 private으로 field와 method를 정의하는 순서는 accessibility rule 또는 visibility rules 또는 permission이라고 불리는데, 이거는 class/object의 어떤 부분이 바깥 세상에게서 접근 가능할지를 결정하는 법칙이다.
accessibility rule은 다음과 같다.
1) private field rule: 보통 field는 private으로 둔다. 이는 사용자 코드로 하여금 object를 undefined state로 가지 않게 만들 수 있다.(e.g. denominator를 0으로 두는 것.) 그러나 private field rule에는 한가지 예외가 있는데, primitive type와 같이 다루는 간단한 object들은 field를 그냥 public에다가 둔다. 왜냐하면 double 이나 int와 같은 built-in primitive type은 사용자 접근으로부터 보호를 받지 않기 때문이다.(e.g. Point.x, Point.y)
client code에 어떤 service를 주는 method들은 class의 public으로 설정한다. 이때 object를 illegal state(i.e. undefined behavior)로 만들지 못하도록 method들을 만들어야 한다.
service method를 도와주지만 바깥 세상에서 쓰의는 것을 의도하지 않은 method들을 helper method 또는 auxiliary(보조) method라고 부른다. helper method는 private에서 정의된다. 이 helper method는 public method를 더욱 간단하고 일관성있게 만든다.
이 encapsulation의 장점에는 여러가지가 있다.
그 중 하나는 1) flexibility in implementation을 준다.
class interface(visible part)는 바뀌면 안된다. 그 이유는 class interface가 바뀌면 그 class를 사용하는 client code를 break할 수 있기 때문이다. 이때 그 class interface가 client code를 break했다고 표현한다.
반면 class implementation(hidden part)은 바뀌어도 된다. client가 볼 이유가 없는 곳이다. 왜냐하면 이 class가 어떻게 돌아가는지는 client의 관심사가 대부분 아니기 때문이다. client의 관심사는 class가 무엇을 하느냐. 즉 class interface이다. 따라서 class implementation 부분을 flexible하게 변경할 수 있다는 장점이 있다.
또한 2) 복잡성을 숨길 수 있고, 3) client가 ill-defined state로 object를 바꿀 수 없게 해 error를 줄여주며, 4) client는 사용하는 class의 복잡성을 알 필요가 없어 object를 돌아가게 하는 class의 복잡성을 고려하지 않아도 되고, 5) class designer는 private 부분만 수정해서 다시 배포해도 되므로 client code의 복잡성을 고려하지 않아도 된다. 즉 client가 class를 어떤 맥락에서 사용해도 되는지 몰라도 된다는 장점이 있다.
그러나 c++의 encapsulation에는 단점이 있는데, 객체를 자신의 method으로부터 보호할 수 없다. 이 말은 무슨 말이냐면 method는 정의된 모든 class member에 대해 접근할 수 있다. 따라서 class의 어떤 부분은 몇몇 method로부터 보호받아야 한다고 생각하면 그 class를 몇개의 class로 나누어 구성해야 한다.
Ch.15. Fine tuning objects
this (pointer)는 사실 모든 method에 전달되는 implicit parameter다.
const
우리가 사용자 정의형 data type을 이용해 어떤 객체를 const로 정의했다고 했을 때, 그 const object에 대해 모든 method를 사용을 못할까? 아니면 data member를 수정하는 method만 사용하지 못할까?
답은 '모든 method를 사용하지 못한다' 이다. 왜 그럴까? 그 이유는 compiler는 특정 method가 어떤 일을 할지 모르기 때문이다.
따라서 어떤 method가 object의 상태를 변경시키지 않도록(== data member, private 부분을 변경시키지 않는 method) 정의하려면, 그 method는 const로 선언이 되어야 한다.
const로 선언하게 되면, method를 object의 상태를 변경시키지 않도록 정의했는데, object를 변경시키는 code가 들어간 경우 심각한 logic error를 갖게 되는데, 이를 방지할 수 있다.
method에 const를 선언하는 방법은 int func() const {return ...} 이다.
non-const/const method과 non-const/const object의 관계를 알아야 한다. const object는 const member를 사용할 수 있지만, non-const member를 사용할 수 없다. 그러나 보통의 object(non-const object)는 const / non-const method를 둘다 사용할 수 있다.
따라서 정리하자면 const object는 non-const member를 사용할 수 없고,나머지 const object는 나머지 method를 사용할 수 있다.
const function(member function) overloading: const method와 non-const method는 overloading 할 수 있다. 그 이유는 그 class의 object가 const object인 경우 const function이 실행되고, class의 object가 non-const object인 경우 non-const function이 호출되기 때문이다. 즉 두개의 함수는 별개의 함수라는 것이다. (function 뒤에 const를 붙이는 것은 method에서만 그렇게 한다. 왜냐하면 function 뒤에 붙는 const keyword는 const object가 유일하게 invoke할 수 있는 method로 만들어주기 때문이다.)
ODR은 one definition rule의 약자로, 한번만 정의해야 한다는 뜻이 있다. 한번만 header file을 포함시키는 방법은, #ifndef COUNT_H_ #define COUNT_H_ #endif 이다.
나중에 debugging할 때 #define DEBUG #ifdef DEBUG ..실행코드.. #endif 하면 전처리기가 debug일 경우 실행코드를 포함시켜준다. 더 구체적인 것은 구글링.
Static member
한 class에 하나만 생성이 됨.
class 내부에서 static 변수를 정의하면, 모든 그 class object에 대해 동일한 static 변수를 공유한다.
static 변수는 특이하게도 class 선언 외부에서 정의되어야 한다. 예를 들어 class 이름이 Widget이고 private에 static int quantity;라고 선언되었으면 항상 class 선언 밖에서 static int Widget::quantity = 1; 라고 정의해주어야 한다.
그러나 static const 는 class 선언 외부에서 정의할 필요가 없다. 예를 들어 static const int RED = 1;라고 바로 정의가 가능하다.
static method도 있다. static method들은 non-static members (non-static variable and non-static method)를 접근할 수 없다. 그 이유는 class object 없이 호출할 수 있기 때문이다. 오직 static member들만 접근이 가능하다. 그러나 non-static method는 static/non-static member를 모두 접근 가능하다.
모든 non-static method들은 this라는 implicit parameter를 갖는다. static method는 this parameter를 가지지 않는다.
static method는 class 선언 내부에서 정의가 가능하다.
friend
friend function은 class 내부 function이 아니다. free function(non-member function)이다.
class 선언 밖에서도 private member를 접근하기 위해 friend를 사용한다. class 내부에서 friend int func() {}선언하고 함수 밖에서 friend keyword를 빼고 정의하면 된다.
private 부분에 선언하던지 public에 선언하던지 차이가 없다. 주로 public에 선언하는 것 같다.
friend class Gadget라고 class 선언 내부에 선언할 수 있다. 그러면 Gadget이라는 class 정의에서 friend를 선언한 class의 private member에 접근이 가능하다.
friend std::ostream& operator<<(std::ostream& os, const X& x) {os << ...; return os;}
operator<< overloading(중복정의)의 std::ostream formal parameter에 const가 붙으면 안되는 이유는 cout 출력 오류 뜨는 경우 ostream 객체가 수정이 되기 때문이다.
friend의 관계는 자동적으로 대칭적(symmetric) 관계가 아니다. class 선언 내부에서 friend class A;를 하게 되면 A만 자기의 private를 접근할 권한을 얻지만, 자기는 A의 private를 접근할 권한을 얻지 않는다. 사실 friend가 아니라 상하관계다.
또한 friendship 관계는 전이(transitive) 관계가 아니다. A가 B의 private 접근 권한이 있고 B가 C의 private 접근 권한이 있을 때 A가 C의 private 접근 권한을 가지지 않는다.
좋은 객체지향 디자인은 friend를 잘 사용하지 않는다. 그 이유는 encapsulation을 약화시키기 때문이다. friend는 ill-defined state를 만들 가능성이 더 커지기 때문이다.
Operator overloading
non-member function(전역 scope에서 정의하는 방법)으로 정의하는 방법과 member function으로 정의하는 방법이 있다.
non-member function으로 정의하는 방법은 A operator+(A a, A b) {} 이고
member function으로 정의하는 방법은 A operator+(A b) {}이다.
operator overloading에 대한 더 많은 정보는 여기서->(https://stackoverflow.com/a/4421719)
Ch.16. Building some useful classes
- 생략
Ch.17. Inheritance and polymorphism
Inheritance
상속은 is a 관계로 표현될 수 있다. 인간 is a 동물. 이때 무엇이 derived class고 무엇이 base class일까?
인간이 derived class다. 동물에서 인간이 파생되었기 때문에다.
즉 derived class is a base class이다.
derived->base. 이렇게 화살표로 나타낼 수 있는데, 이것은 derived가 base에 포함되어 있다고 이해해도 된다. 그렇기 때문에 derived is a base가 성립하는 것이다.
그러나 derived class는 base class를 상속받았고, 더 많은 정보가 추가되었으니 derived class가 base class를 포함하는 것이 아닌가?
아니다. derived class는 base class보다 더 많은 정의들을 가지고 있다 보니 그 class가 구현할 수 있는 대상이 줄어드는 것이다. 즉 인간은 동물의 정의에 더 많은 정의들을 가지고 있으므로 더 적은 부분집합을 가질 수 밖에 없는 것이다.
Base b; Derived d;에서 b=d;는 되지만 d=b;는 되지 않는다. 그 이유는 assignment operator는 associativity가 right에서 left이기 때문에 대입이 오른쪽에서 왼쪽으로 된다. 따라서 대입되는 방향이 왼쪽이 되므로 b<-d가 맞고, d가 b에 포함되어야 하므로 b=d만 된다.
구체적인 이유는 d가 b에 비해 더 많은 정의를 가지고 있는데 b에 d의 정보가 할당될 때 b의 정의만 남겨둔 채로 나머지 정의들은 다 버릴 수 있기 때문이다. 반면 d=b;를 하게 되면 b의 정의가 d의 정의를 다 충족시키지 못해 오류가 뜬다.
b=d;는 되지만 d=b는 안되는 것을 upcasting이 된다고 하고, downcasting이 안된다고 한다. 그 이유는 base class가 위에 있다고 생각해서 그런 것 같다.
class B {}; class D : B {}; 하면 자동으로 private으로 상속됨. class D : public B1, public B2 {}; public으로 선언할꺼면 이렇게 해야 한다.
상속은 한 방향으로 밖에 움직이지 않는다. class D는 B의 method를 물려받지만 class B는 D의 method를 물려받지 않는다.
Polymorphism
Base와 Derived class가 있다고 하자. virtual method가 pointer에 의해 invoke되지 않는 이상(포인터를 사용하지 않고 일반 Base/Derived object 사용하거나, 포인터를 사용하여 virtual method가 아닌 method를 부를 때), static binding/early binding이 된다. 이 static binding은 virtual 함수를 썼을 경우를 보면, 어떤 class의 override된 함수를 호출했는지 확인하고 compile된 위치로 이동한다.
그러나 virtual method가 pointer에 의해 invoke되면 컴파일러가 아닌 실행 프로그램이 어떤 코드를 실행할지 결정한다. 이 process를 dynamic binding/late binding이라고 한다. 만약 동적 바인딩이 일어나지 않았다면, 즉 정적 binding은 compiler가 모든 변수의 자료형을 기억한 다음에 그 자료형의 method가 compile된 기계어를 찾아가 그 자료형의 함수를 호출한다.
그러나 상속과 is a 관계는 일을 더 복잡하게 만들었다.
Base *p_b, *p_d, b(initialized); Derived d(initialized); p_b = &b; p_d = &d; 이때 overiding된 virtual method를 사용했을 경우 (p_b->func(), p_d->func()), 둘 다 같은 Base 형 pointer임에도 불구하고 다른 값이 나온다.
그 이유는 다음과 같다. 만약 class가 적어도 하나의 virtual method를 가지고 있다면, 그 class의 instance는 한가지 hidden field(data member)를 갖게 된다. 그 hidden field는 virtual method pointer 배열을 가르키는 pointer라고 한다. 이거를 vptr이라고 밑에 사이트에서는 부르고 있다. 이 vptr은 vtable(virtual method pointer들의 배열)을 가르키고 있다. 컴파일러는 class의 virtual method에 index를 배정한다. 그리고 vtable[0] = get(), vtable[1] = append() 처럼 index를 배정하는 것이다. 따라서 p_b->get();을 하면 p_b->vtable[0]();을 호출하는 것과 같다.
따라서 p_b = &b; p_d = &d; 했을 경우에, b,d 객체는 이미 vptr를 가지고 있었고, p_b = &b; p_d = &d; 과정을 통해 d의 시작 주소가 p_d로 갔고, p_d에는 d의 vptr field도 가지고 있기 때문에, 같은 Base형 포인터임에도 불구하고 다른 결과가 나온 것이었다.
더 많은 정보는 여기서: (https://www.geeksforgeeks.org/virtual-function-cpp/)
Virtual
virtual keyword는 파생 class에서 새롭게 정의하는 것을 class designer가 계획하고 method에 쓰는 것이다.
순수 가상 함수는 반드시 정의되어 있어야 한다. 선언만 있을 경우 error. 따라서 빈 괄호 {} 라도 적어주어야 한다.
순수 가상 함수가 아닌 모든 가상 함수는 반드시 derived class에서 구현될 필요가 없다. (https://stackoverflow.com/a/8931719)
순수 가상 함수(pure virtual functions/methods)는 virtual void func() = 0; 형태로, 함수(선언) = 0; 형태로 쓴다. 순수 가상 함수가 한개라도 들어가는 class를 abstract class, 추상 class라고 한다. 반면 순수 가상 함수가 하나도 들어가지 않은 class를 concrete class라고 한다. 이 추상 class는 자신의 instance를 절대 만들 수 없다. 그 이유는 이 추상 class는 하나의 abstract concept이기 때문이다. 즉 하나의 추상 컨셉/아이디어이기 때문이다. 이렇게 추상 클래스를 c++에서는 정의한 것이다. 따라서 순수 가상 함수를 쓴 추상 클래스를 상속받는 derived class는 반드시 이 함수를 override해 주어야 한다. 안그러면 오류가 난다.
더이상 virtual 함수를 override하지 않게 하려면 override 대신 final을 쓰면 된다.
override나 final은 context-sensitive keyword다. method에 header 부분에 쓰이지 않는 이상 보통 식별자로 사용될 수 있다는 의미다.
override를 쓸 때면 virtual keyword를 같이 써도 된다.
override나 final의 사용은 선택사항이다. C++11 이전에는 그냥 계속 virtual keyword를 통해 override를 했다. 그러나 만약 base class에 있는 함수의 signature와 다르게 base class에 적었다면 그 함수는 overriding 되지 않고 overloading이 된다. 이게 골치아픈 문법이 있는 것 같긴 한데, 어쨋든 이걸 방지하기 위해 override가 나온 것이다. override를 쓰게 되면 base class에서 함수 signature를 잘못 쓰더라도 error가 뜨게 된다.
base virtual method를 override 할 때면 virtual keyword를 사용하지 않아도 된다. 그러나 이 방법은 권장되지는 않는데, 그 이유는 이게 virtual method인지를 확인하려면 base class를 봐야 하기 때문이다.
B라는 class의 method에 virtual std::string get() const; 선언할 때만 virtual keyword를 사용해도 된다 (virtual std::string get() const {};인 구현 부분에서는 사실 virtual keyword를 생략해도 된다.) override 도 virtual과 마찬가지로 선언할 때에만 사용해도 된다. method를 정의할 때에는 생략하고 사용 가능하다는 뜻.
function overriding이 function overloading이 된다?
base class에 있는 함수를, derived class에 함수 이름은 갖고 signature는 다르게 overloading하면, derived class instance를 통해 접근할 경우 base class에 있는 method는 숨겨진다. 이때 base/derived class의 method는 virtual/non-virtual 다 상관없다. (virtual or non-virtual method in base class gets hidden when overloading virtual or non-virtual function in derived class)
구체적인 설명: (출처: https://stackoverflow.com/a/8816835) Base class의 public method void func(double b) {};가 있다. public으로 파생된 Derived class의 private method void func(char d) {};가 있다. 이때 두개의 함수는 모두 virtual이던 아니던 상관 없다. 이때 Derived* d = new Derived(); Base* b = d; 이때 b->f(65.3);는 func(double b)를 호출하고 d->f(65.3);는 func(char d)를 호출한다. 이유는 무엇일까? func(double b)는 private으로 상속받고 base class에서도 private으로 정의되었으면, func(char c)와 같이 base class에서 접근이 가능했을 것이고, function overloading이 일어나야 될 것 같다. 그래서 b->func(65.3)은 func(double b)를 호출하는 것이 맞지만, 65.3은 double이라 b->func(65.3)은 func(char d)를 호출할 것 같기 때문이다. 그러나 derived class에서 함수 이름은 갖고 signature가 base class와는 다르게 정의하게 되면 base class에 있는 method는 숨겨지게 된다. (비록 base class에 있는 method가 virtual이 되어서 overloading이 될 것 같아도 말이다.) 이것이 왜 그렇게 되는지는 잘 모르겠지만, 어쨋든 문법이니깐 외워야 할 것 같다.
Public, protected, private - access specifiers, access modifiers
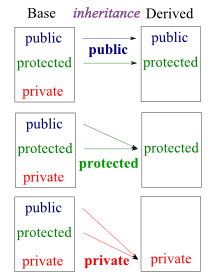
Base class가 있고 1) public으로 Base class를 상속받은 class Derived가 있다고 하자.
private: Base class의 member에 private 접근 지정자를 씌우게 되면 그 member들은 derived class 밖에서 접근할 수 없고, derived class 내부에서도 접근할 수 없다.
public: Base class의 member에 public 접근 지정자를 씌우게 되면 그 member들은 derived class 밖에서도 접근할 수 있고, derived class 내부에서도 접근할 수 있다.
protected: Base class의 member에 protected 접근 지정자를 씌우게 되면 그 member들은 derived class 밖에서 접근할 수 없지만, derived class 내부에서는 접근할 수 있게 된다. 즉 protected는 inheritance를 위해 private과 public 접근 지정자를 섞어서 만든 접근 지정자다.
2) 그렇다면 Derived class에 protected로 Base class를 상속받은 경우는 어떨까?
그 경우 모든 public과 protected으로 선언된 Base class의 member들이 Derived class 내에서는 접근 가능하지만, derived class 밖에서 접근할 수 없게 된다. 여기서 base class에 member들이 모두 private, protected로 설정이 되어있을 경우, public/protected base class를 상속받는 것은 같은 효과를 낸다. 그러나 특별한 점은 base class의 member가 모두 public으로 설정된 경우다. 이때 public이 아닌 protected로 상속받게 되면 derived class 외부에서 접근할 수 없게 되는 반면 derived class 내부에서는 접근할 수 있게 된다.
3) 그렇다면 Derived class에 private으로 Base class를 상속받은 경우는 어떨까?
그냥 base class를 public/protected/private 어떤 접근 지정자를 사용했던지 derived class 외부/내부에서 모두 접근이 불가능하다. 과연 쓰일 일이 있을까 생각이 되긴 하긴 하는데 밑의 사진 링크에 보면 쓰이는 곳이 있을 수는 있는 것 같다.
 </img>
</img>(P.S. access specifier는 class level에서 작동한다. object level에서 접근 지정자가 작동한다고 생각하지 쉽지만 말이다. 출처: https://stackoverflow.com/a/17721201)
Alternative to inheritance and polymorphism
상속과 다형성의 장점은 std::vector<Base *> vec; 형태로 vector를 만들고, class Derived1, Derived2, ...등에 상관없이 vec.push_back(&derivedObject)를 할 수 있다는 것이다. 그걸 통해 base class에 적당한 virtual function이 있으면, 그것을 통해 모든 class instance를 제어할 수 있는 것이다. 예를 들어 terran 종족만 모두 갑자기 소리를 지르게 하고 싶을 때, 상속과 다형성을 이용해 그렇게 만들 수 있을 것 같기도 하다.
따라서 상속과 다형성의 장점은 포인터에(ptr 크기: 4byte, 32-bit 운영체제)에 더 많은 정의를 담고 있는 자식 클래스의 정보를 다 담을 수 있다는 것에서 나온다.
만약 그러지 않는다면 derived class의 나머지 field를 slice할 것이다. 따라서 포인터 배정이 slicing 문제를 avoid해 준다는 것을 알 수 있다.
그러나 사실 상속과 다형성을 대체할 수 있기는 하다. 그런데 그걸 하려면 비교적 안좋다. 상속과 다형성을 회피하여 만든 프로그램과 비교했을 때 상속과 다형성을 사용한 프로그램이 더 좋은 이유를 알아보자.
1) 각각의 derived class들이나 base class는 추가적인 field를 가지지 않는다. memory를 아낄 수 있다는 것이다.
2) 새로운 기능을 추가하기 위해 base class를 수정하지 않아도 된다. 오직 base class 하나만 더 만들면 된다.
3) 모듈화가 가능하다. 이말이 무슨 말이냐면 base class의 header file만 있어도 derived class를 구현 가능하다. 즉 base class의 interface(method 종류)만 가지고 있어도 된다. base class의 cpp file은 만약 compile된 파일이 있다면 필요 없다. 그냥 link 과정만 있으면 되기 때문이다. 단 base class를 이용하고자 하는 모든 client는 base class의 header file은 반드시 필요하다. (base class에 virtual 함수가 많아야 가능한 일일 것 같긴 하다.)
Adapter design pattern
만약 class X 와 class Y를 가지고 있고 이 두개의 class가 기능적으로는 거의 비슷한데 interface가 다른 경우(different method), 또는 라이선스 문제가 있는 등의 우리가 class Y가 어떻게 돌아가는지 수정/control할 수 없는 경우
class Y를 수정할 수 없어서, class Z를 Y처럼 쓰고 싶다면, 그럴 때 adapter design pattern을 쓰면 된다.
class Z 활용 부분에서는, Y의 함수를 작동시키지만 X의 interface(method)로 작동되는 class Z와 class X를 동시에 관리하기 위해 X형 포인터를 원소로 가지는 vector를 만들고, vector에 class Z instance를 push_back해준다. 그럼 xvec[0]->(method) 형태로 함수를 동시에 호출할 수 있다.
Constructor, destructor call sequence
생성자와 소멸자가 호출되는 시기는 언제일까?
c->b->a 형태의 class가 있다고 해보자. c는 b를 상속받았고 b는 a를 상속받았다.
이때 생성자는 a,b,c 순서로 호출되고 소멸자는 c,b,a 순으로 호출된다.
즉 생성자는 부모부터 호출되고, 소멸자는 자식부터 호출된다.
왜 이렇게 설계되었냐면, 자식 class(sub-class)는 부모의 field를 사용할 수 있기 때문이다. 따라서 부모의 생성자가 먼저 호출되어야 부모의 field가 초기화가 되고, 그래야 초기화된 부모의 field를 자식이 사용할 수 있는 것이다.
Constructor, member initializer list
Derived class의 생성자에서 Base class의 생성자를 호출해야 하는 경우, 반드시 member initializer list를 이용해 Base class의 생성자를 호출해 주어야 한다. 그 이유는 c++ 문법이 그렇기 때문이다. 만약 이렇게 base class의 생성자를 초기화 리스트를 이용해 derived class의 생성자에서 호출하지 않으면 default 생성자가 호출이 된다.
또한 초기화 리스트가 아니라 derived class의 생성자 함수 내부에서 생성자를 호출할 경우 그냥 그 함수 scope 내에서 만들어지는 지역 변수가 생성된다. 그러면 base class의 변수는 초기화하지 못하게 된다.(더 많은 내용은 여기서: https://stackoverflow.com/a/7810306)
또한 base class의 생성자 호출을 초기화 리스트에서 할 때 초기화 리스트중 가장 먼저 나와야 한다. 그 이유는 문법이 그렇다. 아마 base class의 생성자가 먼저 호출이 되고 다른 derived class의 member가 초기화가 되어야 해서 그런것이 아닐까 싶다.
member initializer list를 반드시 사용해야 하는 경우: (https://stackoverflow.com/a/8523361)
Copy constructor, assignment operator in classes, shallow / deep copy
배경:
member 변수로 포인터 변수를 가질 때 명시적 copy constructor가 필요하다. 그 이유는 그냥 대입 연산자를 하게 되면 그 주소값이 포인터로 대입이 되기 때문에 같은 주소값을 가져 같은 곳을 가르키게 되기 때문이다. 이것을 shallow copy라고 한다. 따라서 pointer를 data member로 가지지 않는 경우 copy constructor가 필요하지 않다. deep copy, shallow copy의 개념은 여기서 파생된 것이다. deep copy는 서로 다른 복사본 두개를 만드는 것이고, shallow copy는 서로 다른 포인터 data member가 같은 주소값을 value로 가질때, 실제 변수는 두개지만 1개만 가르키게 만드는 것이다.
따라서 deep copy, shallow copy는 pass by reference, pass by value 개념과 다르다. shallow / deep copy는 (포인터 변수를 member data로 가지는) 객체의 복사에 대한 얘기고, pass by reference / value는 객체의 전달에 대한 얘기다.
만약 어떤 객체를 pass by reference로 보낸다면(passing object by reference), 복사는 일어나지 않는다. 그러나 어떤 object를 pass by value로 보낸다면, 객체가 복사된다. 이때 객체가 포인터가 아닌 변수들만 field로 가지고 있다면 객체 복사는 아무 문제 없이 별개의 객체로 잘 복사가 된다. 그래서 shallow copy와 deep copy라는 개념이 포인터 변수가 아닌 변수에서는 존재하지 않는다는 것이다. 기본 대입 연산자는 member들끼리 단순하게 복사시켜 준다. 이때 포인터인 멤버 변수가 단순하게 복사된다는 것은 포인터값이 서로 복사가 된다는 것이고 따라서 같은 객체에 대한 두개의 포인터가 만들어진다는 것이다. 즉 이 두개의 포인터는 이름만 다를 뿐 같은 객체를 가르키데 된다. 이게 shallow copy다. 대입 연산자는 pointer를 member data로 가질 경우 default로 shallow copy가 된다.
만약 포인터 멤버 변수가 가르키는 sub-object가 온전히 자신 class의 객체가 되도록 만들고 싶다면 deep copy가 필요하다. deep copy는 pointer를 member data로 가질 경우 복사되는 객체의 포인터 member data가 서로 다른 object를 가르킬 수 있도록 하는 것이다. 왜냐하면 shallow copy는 복사를 하게 되면 복사를 한 모든 객체에 대해 포인터 멤버 변수는 모두 한 sub-object를 가르키게 되기 때문이다.
따라서 이를 위해선 custom copy constructor와 custom assignment operator를 구현해야 한다.
(P.S. access modifier,접근 지정자는 class level에서 작동하지, object level에서 작동하지 않는다. 따라서 copy constructor의 parameter의 객체의 private 변수들을 마음대로 접근할 수 있다.)
문법:
default copy constructor: 복사 생성자를 명시적으로 정의 안하면 묵시적으로 복사 생성자가 정의가 된다. 이 복사 생성자를 default copy constructor라고 한다.이거는 shallow copy다. 왜냐하면 이 default copy constructor는 assignment operator를 overloading한 것과 같은 기능을 보이기 때문이다. 즉 복사 생성자를 명시적으로 정의 안한 상태에서 Derived ob1(ob2);를 하게 되면 ob1 = ob2;와 같은 의미다. 이 현상은 assignment operator를 overloading해줘도 동일한 현상이 나타난다.
복사 생성자의 문법은 다음과 같다. Derived class 내의 public 부분에 Derived(const Derived& d) { delete []data; data = new int[n]; for (int i = 0;i < n; i++){this->data[i] = d.data[i]}} (*(this->data) = *(d.getData());) 라고 정의. (여기서 data는 동적으로 할당된 배열) 여기서 무엇이 중요하냐면 복사 생성자의 formal paramter의 const와 &를 반드시 써주어야 한다.
또한 복사생성자를 명시적으로 정의하게 되면 대입 연산자도 overloading하는 것이 좋다. 그 이유는 대입 연산자로 객체를 복사할 때 deep copy로 하기 위해서다. 대입연산자 overloading 문법은 다음과 같다. Derived& operator=(const Derived& d) {if (this != &d) { delete []data; data = new int[n]; for (int i = 0;i < n; i++){this->data[i] = d.data[i]}}return *this;} (배열이 아니면 for loop 대신 *(this->data) = *(d.getData());)
위의 대입연산자 overloading에서 self assignment check을 해야하는 이유: 왜 if (this != &d) {...}를 해야 하는가? 그 이유는 만약 같은 객체 ob1 = ob1;을 하게 되면 어떤 일이 벌어지냐면, 먼저 내부적으로 lvalue인 ob1의 값이 파괴된다. 그 다음 rvalue 값을 lvalue에 대입해야 하는데, rvalue가 파괴되어 logic error가 발생한다. (사실 정확하게 말하면 lvalue인 ob1의 memory를 release해주는 것이다(≈값 파괴). 왜 그런거냐면, 실제 우리가 overloading하는 assignment operator를 보자. 맨 처음 하는 것이 delete[] data;이지 않는가. 따라서 대입 연산자의 수행은 항상 먼저 lvalue의 delete이 이루어져야 하는 것을 알 수 있다. 참고: https://www.geeksforgeeks.org/g-fact-38/) (만약 well-designed operator를 만들고 싶다면, 또는 if condition check를 하지 않고 lvalue의 memory release를 방지하고 싶다면, 지역변수 int *new_data = new int[n]를 만들어서 거기에 대입 연산자의 rvalue를 대입하고, lvalue를 delete한다. 그 다음 this->data에 = new_data를 해주면 self-assignment check이 필요없이 self-assignment하는 도중 lvalue가 삭제되는 문제가 해결된다. 그러나 이 방법은 performance적으로 좋은 방법은 아니다. 왜냐하면 모든 assignment에 대해 쓸데없는 지역변수가 만들어지기 때문이다. 참고: https://stackoverflow.com/a/12015213)
복사생성자가 호출되는 경우와 대입연산자가 호출되는 경우:
1. Derived ob1(ob2); 는 복사생성자가 호출됨.
2. Derived ob1 = obj2; 는 복사생성자가 호출됨. (copy elision 때문)
3. ob1 = obj2; 는 대입연산자가 호출됨.
복사생성자 문법에서, formal paramter에 const를 붙여야 하는 이유는 무엇일까? 그 이유는 (https://www.geeksforgeeks.org/copy-constructor-argument-const/)
이렇게 복사 생성자로 member를 초기화하는 경우 copy initialization이라고 한다.
copy constructor in cpp(https://www.geeksforgeeks.org/copy-constructor-in-cpp/)
copy elision in cpp(https://www.geeksforgeeks.org/copy-elision-in-c/)
copy elision and return value optimization: (참고: https://stackoverflow.com/a/12953129)
Ch.18. Resource management
code, data, heap, stack
memory는 4개의 영역으로 나뉘어져 있다. code, data, heap, stack이다. Data는 global variable과 static(persistent local variable) variable을 갖는다.
1. code는 executable instruction를 가지는 memory부분이다. code section의 content는 실행되면서 절대 변경되지 않아야 하며, code segment의 size도 프로그램 실행과정에서 변하지 않는다.
2. 메모리의 data section은 global variable과 static(persistent local variable) variable을 갖는다. 이 변수는 프로그램 실행이 끝날 때까지 data section에 존재한다는 특징이 있다. 변수가 const가 아닌 이상 그 값을 자유자제로 바꿀 수 있기 때문에, data section의 content는 실행되면서 변경될 수 있지만, data segment의 size는 변경되지 않는다. 이것을 할 수 있는 이유는 프로그램의 소스 코드가 global/static 변수의 개수를 정의하기 때문에, data segment의 정확한 size를 compiler가 계산해낼 수 있기 때문이다. global 변수는 run-time environment에서 main 함수가 실행되기 전에 초기화가 되고, main함수가 return될 때 치워진다. static 변수는 static이 들어있는 지역에서 function/method의 첫번째 invocation에서 초기화되고, main함수가 return될 때 치워진다. 반면 non-static local variable들은 함수가 실행될 때에만 stack에 저장된다.
3. heap: new keyword는 heap으로부터 메모리를 가져오고, delete는 할당된 메모리를 heap으로 다시 돌려 보낸다. heap의 size는 동적 메모리를 new/delete를 활용해 allocate/deallocate 하느냐에 따라 자라기도 하고 줄어들기도 한다. heap space는 보통 stack보다 크다. OS가 가상 메모리를 사용하여 시레 메모리보다 큰 메모리를 실행 프로그램이 사용할 수 있다. 가상 메모리는 disk drive로 부터 오는데, 이거는 속도가 느리다. vifrtual memory는 unlimited하지만, memory leak이 발생하는 프로그램이라면 언젠가는 메모리가 부족할 수 있다. heap은 new와 delete로 grow/shrink하는데, new로 새롭게 메모리를 할당한 순서와 다르게 delete할 수 있다. 따라서 heap 공간은 contiguous하지 않다. 그렇기 때문에 heap에서 사용 가능한 memory는 프로그램 실행 동안에 fragmented 될 가능성이 높다.
4. stack: 지역변수와 함수 parameter가 사는 곳이다. OS는 stack의 size를 limit한다. 무한 recursion을 예로 들면 stack의 공간을 모두 잡아먹을 것이다. 이 현상을 stack overflow라고 한다. Modern OS는 stack space를 다 잡아먹으면 process를 중단시키지만, embedded system에서는 stack overflow는 발견되지 않을 수 있다. 따라서 heap 공간이 stack보다 공간이 보통 더 많다.
new, delete 쓰는 방법
모든 new 명령어 사용 뒤에는 더 이상 할당된 메모리가 필요 없어지면 delete를 사용해야 한다.
calc 함수 안에 new가 있는 경우 함수 안에서 delete를 사용하지 않고 run-time error가 일어나지 않게 하는 방법은 총 2가지가 있다. 1. 첫번째는 할당된 메모리에 global 또는 static local pointer를 할당한다. 이 방법은 main함수가 return 될 때까지 살아있으므로 우리가 delete할 필요가 없는 것이다. 2. 두번째 방법은 p를 return하여 function caller가 calc이 만들어낸 object를 다 썼다면 caller가 return할 수 있도록 하는 것이다.
delete operator는 new로 할당되지 않은 pointer에 사용되면 안된다. -> 이거는 undefined behavior라서 logic error.
같은 메모리 공간에 delete를 두번 이상 사용하면 안된다. -> 이거는 undefined behavior라서 logic error.
이미 delete한 메모리 공간에 접근하면 안된다. -> 이거는 undefined behavior라서 logic error.
큰 프로그램을 만들다 보면 multiple delete를 방지하기 사실 쉽지 않다. 따라서 memory allocation을 계속 기록하고 있는 하나의 complex global accounting infrastructure를 구현해야 한다.
Linked list
linked list를 사용하는 client의 main 함수:
Linked List version1: IntList1
Node object 안에 Node를 정의하는 것은 안된다. 그 이유는 compiler는 하나의 object에 특정 size의 공간을 배정해야 하는데, struct Node{ Node p;};를 하게 되면 p는 Node size를 가지는데, 그 size는 또 Node size를 가지기 때문이다. 따라서, Node 안에 Node object를 정의하고 싶다면 struct Node{ Node* p;}; 형식으로 pointer로 정의해주어야 한다. 그 이유는 pointer는 32/64bit 체제에 따라서 고정된 4/8byte 크기를 가지기 때문이다.
위 IntList1 code에서, Node struct는 IntList 안에서 선언되어있다. 이 Node struct를 nested struct(nested class)라고 한다. 이거의 특징은, nested struct 밖에 있는 것들은(외부는) nested struct의 public만 접근할 수 있다. 따라서 intList1의 모든 method는 Node struct의 public에 있는 field, method만 쓸 수 있는 것이다. 다행이 이 경우 Node는 primative data type이라서 모든 member에 IntList1이 접근할 수 있는 것이다.
public method가 private helper method에 일을 위임(delegate)한다고 한다.
client code는 pointer를 전혀 사용하지 않는다. 또한 Node class도 client에서는 보이지 않는다.
if (p) {...} == if (p !=nullptr) {...}이다! if (!p) {...} == if (p ==nullptr) {...}도 마찬가지다. 그 이유는 nullptr가 0/false로 해석되기 때문이다. 이 사실을 이용해서 for(auto cursor = head; cursor !=nullptr; cursor = head->next) {std::cout << cursor.data << ' ';} 에서 cursor != nullptr를 cursor로 그냥 바꿀 수 있는 것이다.
위 IntList1 linked list class의 경우 총 4개의 public method가 있다. 그 함수들은 바로 length, clear, insert, print가 있다. insert는 tail이 nullptr이라면, head = tail = 새로운 Node(data)하면 되고, nullptr가 아니면 tail->next = 새로운 Node(data)하면 된다. print()는 for(auto cursor = head; cursor; cursor = cursor->next) {std::cout << cursor.data;}하면 된다. length, clear는 recursive 형태로 정의되었다. lengthPrivate(Node *p)은 만약 p == nullptr이면 return 0이고 p != nullptr이면 return 1 + length(p->next)이다. length 함수는 lengthPrivate만 호출하면 된다. clearPrivate(Node* p)는 clearPrivate(p->next); delete p;를 하면 되고, clear 함수는 clearPrivate(head);를 하고 head = tail = nullptr;을 해주면 된다.
왜 delete를 하고 head = tail = nullptr;와 같이 nullptr을 배정해주는가? 그 이유는 double delete가 undefined behavior이기 때문이다. masked double delete bug이 undefined behavior보다 더 선호되기 때문에 delete하고 nullptr을 가르키는 습관을 기르는 것이 좋은 것이다.(참고: https://stackoverflow.com/q/1931126) 그러나 사실은 사용할 수 있다면 RAII class를 또는 STL을 사용하거나, delete하고 변수의 scope를 끝내는(지역 변수로 사용) 것이 좋다. 그렇지만 이렇게 하지 못하는 경우 항상 포인터는 delete 후 nullptr를 대입해주는 것이 좋다.
사실 length나 clear를 recursive하게 정의하는 것이 효율적이지는 않다. 함수 호출이 비용이 많이 들어가는 작업이기 때문이다. 따라서 iterative 하게 정의하게 되면, length는 len 지역변수 하나 만들어서 cursor->next가 nullptr가 아닐 때까지 for loop 돌리고 nullptr가 아니면 len++하고 len return하면 된다. clear는 cursor가 nullptr가 아닐 때까지 for loop 돌려서 temp = cursor; cursor = cursor->next; delete temp;하면 된다. 그 다음 head = tail = nullptr까지 하면 된다.
만약 length의 정보를 굉장히 많이 접근해야 하고, 굉장히 큰 list들을 가지고 있거나, list 객체를 별로 만들지 않을 때, length 정보를 담고 있는 member 변수를 class에 추가할 수 있다. 그냥 하나의 정수가 추가되는 것은 좋은 tradeoff이기 때문이다.
destructor
void f() {IntList1 myList; myList.insert(3);}의 함수가 있다고 하자. main함수에서 f()를 호출할 때 memory leak이 발생한다. 왜냐하면 myList는 지역변수인데, head와 tail이 접근할 수 있는 메모리가 scope 밖으로 나가면 더이상 접근할 수 없기 때문이다. 따라서 destructor에서 this->clear();를 해 줘야 한다.
생성자는 new 명령어에서 호출된다. 또한 destructor는 delete 명령어에서 호출된다. 따라서 IntList1 *p;에서는 생성자가 호출이 되지 않는다. p = new IntList1; delete p;해야 생성자/파멸자가 호출되는 것이다.
copy constructor, assignment operator
IntList1 seq1, seq2; seq1 = seq2; 를 하면 어떤 일이 벌어질까? seq2.head가 seq1.head로, seq2.tail가 seq1.tail로, seq2.len이 seq1.len으로 각각의 메모리 주소가 복사된다. 이렇게 되면 3개의 undesirable result가 만들어진다.
1. aliasing: seq1을 수정하면 seq2도 수정된다.
2. memory leak: seq1의 list가 더이상 접근이 불가능하다. seq1의 node를 delete할 수 있는 방법이 없다.
3. memory corruption: 보통 생성자의 호출 순서는 파멸자의 호출 순서와 다른다. 만약 seq1을 seq2보다 생성을 먼저 했으면, destructor는 seq2가 먼저 호출이 된다. 그러나 seq1과 seq2는 같은 객체를 가르키고 있으므로 double delete가 되어서 undefined behavior가 되고, 보통 UB는 memory corruption을 일으킨다. 그래서 seq1 = seq2;를 하게 되면 몇몇의 실행에서는 program이 crash한다.
이를 해결할 수 있는 방법이 있다. 먼저 initialization과 assignment를 구별해야 한다. int x = 3;은 선언과 정의가 동시에 된 문장이다. int x; x = 3;은 선언과 정의가 분리된 문장이다. 선언과 정의가 같이 될 때 그 선언을 initialization라고 한다. 그러나 선언과 정의가 구분되었을 때 정의를 assignment라고 한다. int x{3};은 int x = 3;과 같다.
initialization을 copy constructor(X(const X& other))로 할 수 있다. assignment는 X& operator=(const X& other)로 할 수 있다.
copy constructor와 assignment operator의 차이는 copy constructor는 non-preexisting object로 시작한다는 것이다. 따라서 preexisting list of node를 청소할 필요가 없다. 그러나 non-preexisiting object로 시작하기 때문에 initialization list로 자신의 생성자를 호출해주어야 한다. 반면 assignment operator는 preexisting object에서 시작하기 때문에 반드시 왼쪽 객체(*this)가 delete되도록 보장해주어야 한다. copy constructor와 assignment operator의 문법은 아래와 같다.
operator= overloading에서 어떻게 tempList의 private에 this의 member function이 접근할 수 있을까? 그 이유는 access specifier는 class마다 효과있는 것이지, object마다에게 효과있는 것이 아니다. 따라서 같은 class라면 member function은 local class의 모든 member에 접근 가능한 것이다.(참고: https://stackoverflow.com/a/48861580)
Rule of three
copy constructor, assignment operator, destructor 중 적어도 하나가 필요하다고 class designer가 생각한다면, class designer는 이 3가지를 모두 구현해야 한다. 이 세가지를 모두 한번에 정의해야 하는 이유는 위에 다 정리되어 있다.
Rvalue reference
rvalue란 assignment operator 오른쪽에 나타나는 값이다. rvalue는 assignment operator 왼쪽에 나타날 수 없다. 반면 lvalue는 assignment operator 왼쪽, 오른쪽에 나타날 수 있고, 혼자 나타날 수 있다.
rvalue는 temporary value다. temporary value의 뜻은 자기 문장이 실행될 때에만 뜻이 있는 값이다. 실행 프로그램은 rvalue의 computation 결과를 메모리에 일시적으로 저장하지만, 프로그램은 보통 그 메모리를 reference하지 못한다.
따라서 int& r = x+3;은 불가능하다. 그 이유는 temporary value를 reference variable에 배정할 수 없게 c++가 만들어 놓았기 때문이다. 왜냐하면 r은 x+3 값의 주소를 갖는데, x+3은 그 문장 이후에는 존재하지 않는다. 따라서 temporary value인 rvalue는 reference할 수 없다.
그러나 const int& cr = x+3;은 가능하다. 이 값은 scope에서 벗어날 떄까지 cr이 referencd하는 공간에 일시적인 값 x+3을 저장한다.
따라서 int g(int&n){return 10 * n}에서 g(x+2);는 불가능하지만 int g(const int&n){return 10 * n}에서 g(x+2);는 가능하다.
const int& n = x+3;은 temporary value를 copy를 한번 하고 n에 보낸다.
따라서 만약 copy constructor가 있다고 하고, list object를 return하는 함수 g가 있다고 했을 때, IntList1 list = g();를 하게 되면, list의 copy constructor를 호출하게 되고, 이 과정에서 g()는 assignment의 왼쪽에 갈 수 없으므로 rvalue이기 때문에, rvalue의 값을 const IntList reference 변수에 전달하기 위해서는 복사를 한번 하고 보내준다.
만약 list가 수천개의 node를 가지고 있을 때 이 복사는 cost가 매우 높을 것이다. 따라서 이를 방지하기 위해 rvalue reference가 있다.
rvalue reference는 int&& r = x+3;이다. 이거는 temporary value를 복사 없이 alias할 수 있도록 만들어준다.
이거를 constructor, assignment operator에 추가해 보자. rvalue reference로 인수를 받는 constructor, assignment operator를 각각 move constructor, move assignment operator라고 부르겠다. 그러면 문법은 다음과 같다. IntList1(IntList&& list); IntList& operator=(IntList&& list);
move constructor, move assignment operator의 구현 내용은 아래와 같다
이렇게 구현할 수 있는 이유는 list가 지역 변수이기 때문이다. 이 함수가 끝나면 list는 destructor에 의해 파괴되는데(destructor가 호출되는 시기는 delete이거나 scope 벗어나는 경우), 그렇기 때문에 그냥 swap만 해주면 된다.
c++ Rule of five
copy construction, move construction, destruction, copy assignment, move assignment를 모두 정의하지 않으면 compiler가 value sementics를 support하는 default version을 자동으로 만들어 놓는다.
(value sementics: 서로 다른 이름을 가진 변수 2개는 서로 다른 객체를 가르킨다. reference sementics: value sementics와 반대, pointer와 reference가 referencd sementics에 포함된다. 즉 여기서 value sementics를 support하는 default version의 함수들을 만들어 놓는다는 것은 pointer나 reference 변수가 아닌 일반 변수를 data member로 가졌을 경우 아무 문제 없이 동작하도록 지원된다는 뜻이다.)
그러나 destructor, copy constructor, copy assignment operator 중 하나를 프로그래머가 정의하게 되면, compiler는 자동으로 move constructor 또는 move assignment operator를 만들지 않는다. 이거는 사실 구현을 안해도 된다. 왜냐하면 구현을 안하면 copy constructor의 경우 rvalue를 인수로 받았다고 했을 때 temporary value가 copy constructor에 의해 한번 복사가 된 후, copy constructor가 실행된다는 것이다. copy assignment의 경우도 temporary value가 copy assignment에 의해 복사가 되고 다시 copy assignment가 실행된다.
explicit하게 copy construction, move construction, destruction, copy assignment, move assignment를 정의하는 방법
IntList() = default;
IntList1(int x){}
모든 copy construction, move construction, destruction, copy assignment, move assignment에 = default 또는 delete 붙일 수 있음. IntList() = delete;
smart pointer (#include <memory>)
문법: std::shared_ptr<class> p = std::make_shared<class>(12);
auto p = std::make_shared<class>(12);
p = nullptr;하면 destructor가 호출됨. 그 이유는 std::shared_ptr의 생성자 또는 std::make_shared 함수를 통해 동적으로 생성된 객체는 reference count라는 것을 가지고 있다. 예를 들어 std::shared_ptr 변수 3개가 같은 객체를 가르키고 있다면, 그 reference count는 3이 된다. 그러나 p = nullptr; q = std::make_shared<class>(12); r = nullptr;을 하게 되면 그 reference count는 0이 되어서 객체의 destructor가 호출된다.
placement new
primitive type의 경우 그냥 int* p = new int[10];하면 되었다. 그러나 사용자 정의형 type의 경우 내가 원하는 생성자를 호출하고 싶을 떄가 있다. 내가 원하는 생성자를 배열 안에 호출하고 싶다는 것이다. 그럴 경우:
P.S. 뭔소린지 모르겠다. placement new의 경우 교과서에는 없다. 나중에 advanced c++ 배울 떄 그냥 배워야겠다. (참고: https://stackoverflow.com/a/4756306)
Ch.19. Generic programming
문법: template <typename T, typename N> 또는 template <class T>. template <typename T, int N> 도 가능. 이때 인수 N은 non-type template parameter이다.
선언과 정의를 분리할 때, 항상 template <typename T>를 써줘야 하고, class method를 정의 할 때에는 class<T>::method(){} 처럼 써줘야 한다.
compiler가 template function으로부터 실제 함수 정의를 만드는 과정을 template instantiation (템플릿 인스턴스화)라고 한다.
예를 들어 template <typename T, int N> T scale(const T& value) {return value * N} 이라는 함수가 있을 때 explicitly instantiate해야 한다. scale<int, 4>(5); 만약 compiler가 자동으로 type을 추측할 수 있다면, 굳이 명시적으로 인스턴스화 할 필요는 없어 보인다. 그러나 어쩔 때는 explicitly instantiate하는게 좋을 수도 있다. 하나의 예를 더 들자면 2개의 T type 인수를 가지는 함수가 있을 때 인수를 둘다 정수를 주거나 둘다 소수점을 주면 아무 문제가 없다. 그러나 2/2.2 이렇게 주면 compiler가 error를 만든다.
댓글남기기