Blog Full Notice
back to main page
normalization의 모든 종류들을 알아보자.
motivation: normalization의 모든 종류들을 알아보자.
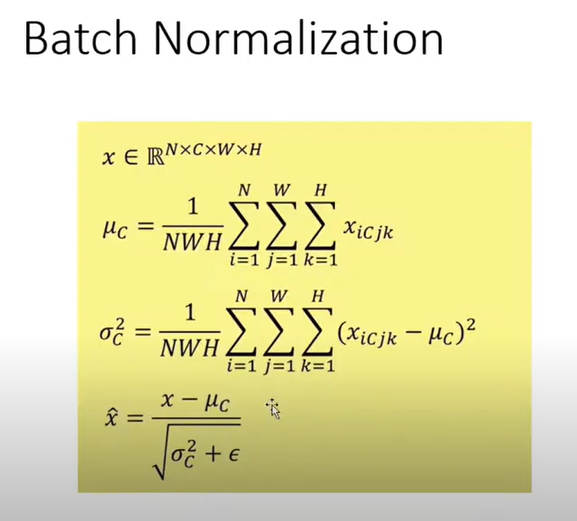
batch normalization은 gradient vanishing 문제를 해결하기 위해서, 평균과 분산을 NN이 정하도록 설정하는 것이다. 그래서 ReLU는 gradient vanishing을 해결하니깐 드라마틱하게 결과가 변하지는 않는데, sigmoid의 경우 BN을 쓰면 굉장히 성능이 좋아진다. 왜냐하면 평균과 분산을 NN이 정할 수 있기 때문.
BN은 근데 inference할 때에는, batch로 data를 넣어주지 않기 때문에, exponential moving average로, 평균과 분산을 결정한다고 한다.(밑의 평균과 분산 정하는 것에서, data를 하나씩 buffer에 저장시켜놓고, 평균과 분산을 구하고, 그 다음에 학습된 hyperparameter(감마와 베타)로 결과를 shift한다.)
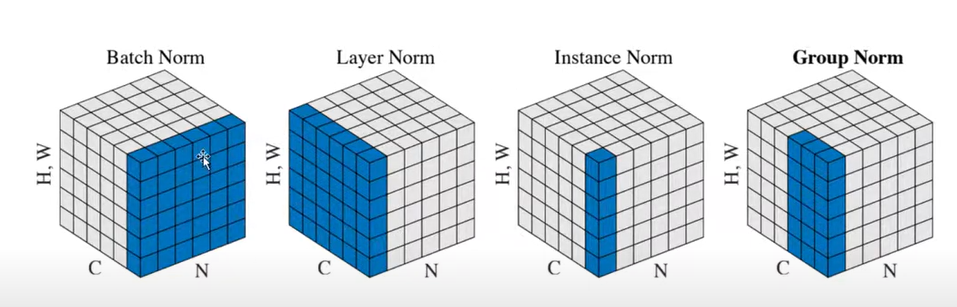
- Batch norm은 batch에 대해서 작용되는 normalization
- Layer norm은 sample 별로 적용되는 normalization
- instance norm sample과 channel 별로 적용되는 normalization
- group norm은 sample과 몇개(조정 가능) channel 별로 적용되는 normalization (instance와 layer norm의 중간)
하나의 layer에 대해서, 적절히, gradient vanishing 문제 해결, 하자. non-linearity도 해결하자. 알아서 이 두개를 NN가 결정하도록 하자. 그래서 layer norm은 layer당 두개의 parameter만 추가되고, training과 test가 똑같이 작동된다. 그리고 batch size에 대해서 영향받지 않는다.
문장 data의 경우, 긴 문장이라고 하자. 문장의 길이가 달라서, pad token을 넣는다. 빈칸에. 그래서 pad가 많아서, batch normalization을 하면, 평균과 분산이 망하게 된다.
근데 (보라색) channel별로 하게 되면, 오히려 더 성능이 좋아진다고 한다. (문장의 읽는 방향 순으로…)

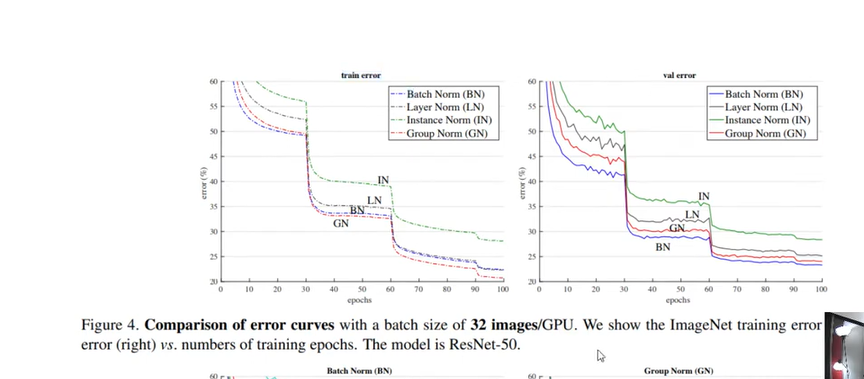 이거를 보면 BN이 가장 성능이 좋고, 그 다음이 GN, LN, IN. (group normalization 이름의 논문에서, validation error, imagenet.)
이거를 보면 BN이 가장 성능이 좋고, 그 다음이 GN, LN, IN. (group normalization 이름의 논문에서, validation error, imagenet.)
문장의 경우, LN이 많이 쓰이는듯.
출처:
댓글남기기