Blog Full Notice
back to main page
deep learning에서 attention의 시초
motivation: deep learning에서 attention의 시초를 알아보자.
1. Seq2Seq
Seq2seq 와 attention 논문 파악하기
seq2seq은
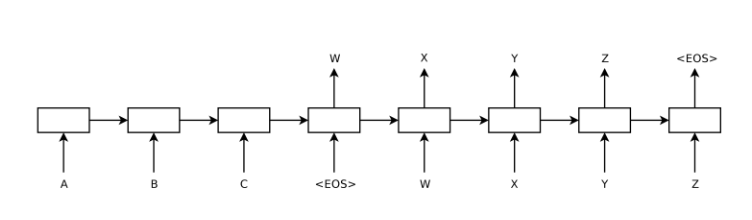 이런 구조를 가짐. 즉 encoder가 출력을 내지 않고, hidden state로의 Vector만 이동시키는 듯.
이런 구조를 가짐. 즉 encoder가 출력을 내지 않고, hidden state로의 Vector만 이동시키는 듯.
2. 바다나우 attention
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE, bahdanau(바다나우), cho,bengio
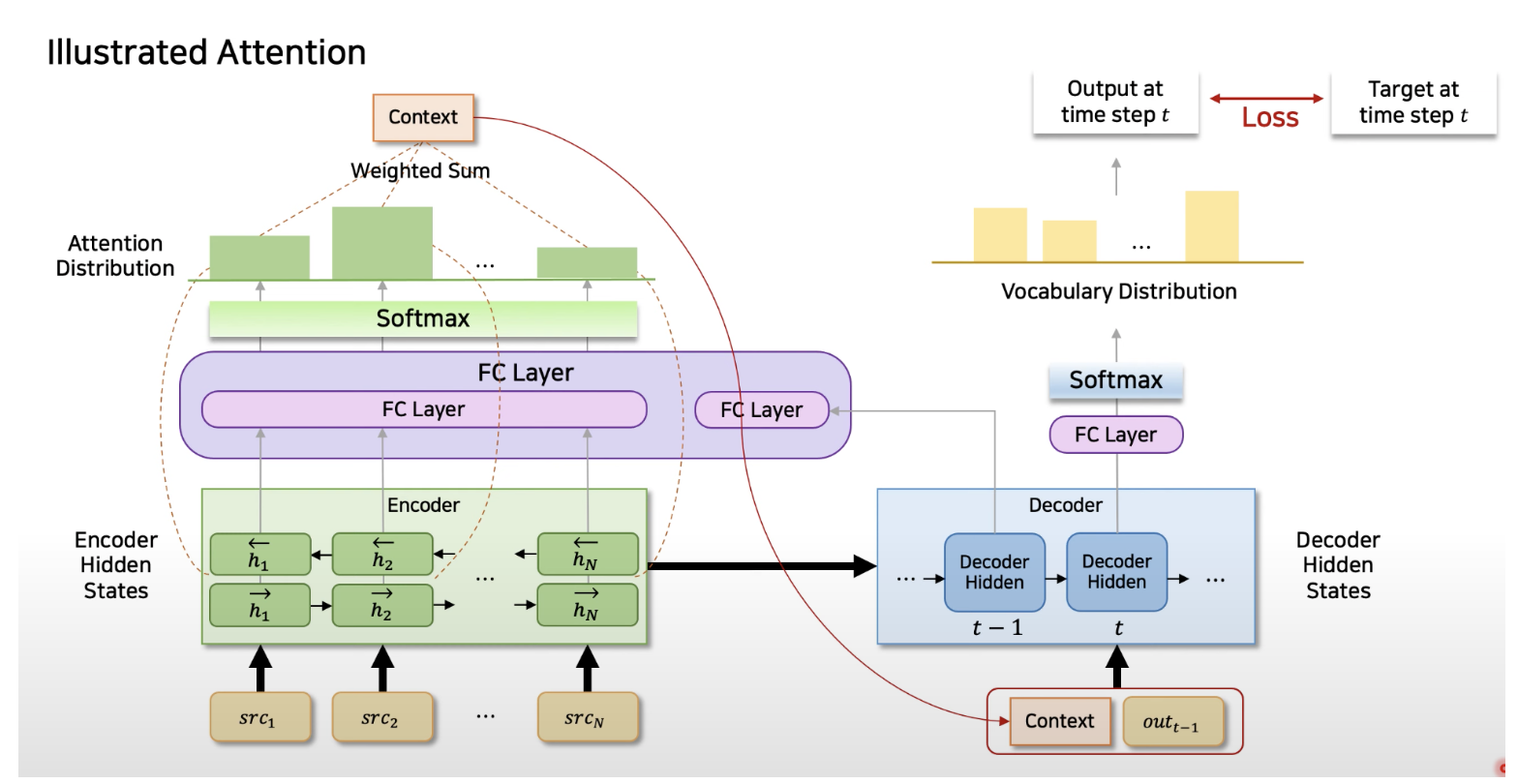
근데 여기서는 이렇게 아키텍쳐가 나온다. encoder가 그냥 hidden vector만 출력하는 것이 아니라, output을 출력을 한다. 그래서 이거를 fc layer를 통과시키고, softmax를 하면 이제 이거를 context라고 부르고,
특히 h1_left, l1_right을 concat을 시켜서, FCL을 통과시키면, 새로운 output을 내는 것이 bi directional RNN인데, 각각의 encoder를 FCL을 통과시켜서, Softmax를 하면, 분포가 생길 것이다.
bahdanau attention 이라고 검색하면 처음 attention을 알 수 있음. (https://yjjo.tistory.com/46) (https://tigris-data-science.tistory.com/entry/DL-%EC%89%BD%EA%B2%8C-%ED%92%80%EC%96%B4%EC%93%B4-Attention-Mechanism-1-Bahdanau-Attention) 결국 바다나우 attention은 attention의 시초고, 또한 softmax를 통해서 context를 주는 것을 볼 수 있음.
3. 생물학적 attention 설명
Shared mechanisms underlie the control of working memory and attention, nature, 2011, Matthew F Panichello), Timothy J Buschman
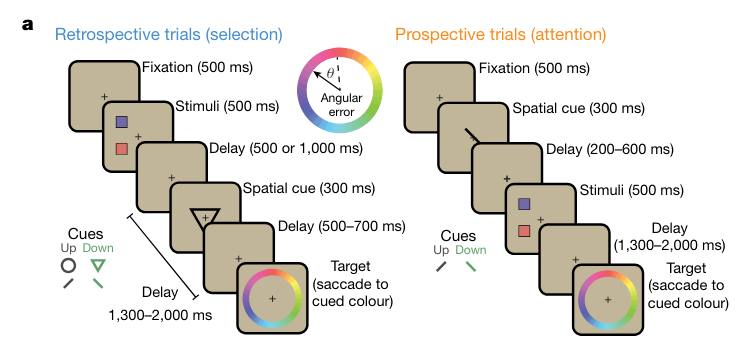 에서, attention을 쓰는 task, WM를 dominant하게 쓰는 task를 나누어서, 먼저 data를 반으로 나누어서,
에서, attention을 쓰는 task, WM를 dominant하게 쓰는 task를 나누어서, 먼저 data를 반으로 나누어서,
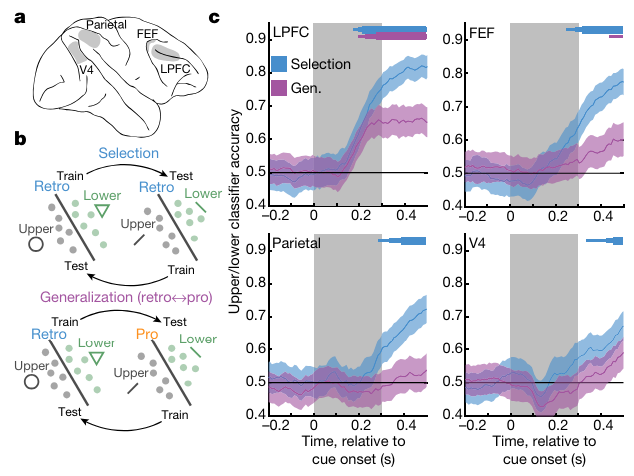
WM(retrospective)를 dominant하게 쓰는 것의 data를 먼저 학습을 진행한다. 그렇게 학습한 classifier가 파란색이다.
classifier 학습은 logitstic regression classifier로, 입력이 population firing rate이고, 출력이 위 또는 아래 다. 결국 예를 들어서, LPFC에서 neuron firing rate이 컸을 때, 출력을 맞췄으면, memory를 쓰는 task에서 LPFC를 더 많이 쓴다는 것.
즉 accuracy가 높을수록, 그 위치가 쓰인다는 것이다. 그 위치가 즉 memory에 쓰인다는 것.
그런데 memory(retrospective)하게 학습한 classifier를, prospective한 실험에서의 data(population firing rate)에 적용하게 되면, accuracy가 높다는 것은, firing rate이 비슷하다는 것.
다른 data(retro, pro)한데도, firing rate이 비슷하게 나온다는 것은, 그 부위는 memory와 attention을 동시에 수행하고 있다는 것.
LPFC에서는 attention과 memory가 동시에 수행이 된다.
4. 사실 cell 수준에서 working memory(STM)이 존재한다는 증거는 있음.
각각이 하는 일에 대해서, 각각이 하는 역할에 따라 다르지만, WM는 모든 부위에서 존재함. 근거 1: Neuronal spike-rate adaptation supports working memory in language processing 근거 2: The Distributed Nature of Working Momory: “signals in all cortical regions can exhibit a short-term buffering of information, depending on the nature of the task.”
Hebbian Deep Learning Without Feedback 코드 사이트: https://github.com/NeuromorphicComputing/SoftHebb?tab=readme-ov-file#abstract-iclr-2023—multilayer-learning (여기에 논문 3개 있는데, 하나씩 다 읽어봐도 좋을듯.)
The Forward-Forward Algorithm: Some Preliminary Investigations 코드 사이트: https://github.com/mpezeshki/pytorch_forward_forward
댓글남기기