Blog Full Notice
back to main page
dacon competition baseline code, random성 고정 방법
motivation: dacon competition의 baseline code를 이해하고, random성 코드를 아카이빙 하기
1. 데이터 다운
pip install gdown gdown https://drive.google.com/uc?id=1hi1dibkHyFbaxAteLlZJw6r3g9ddd4Lf
(https://drive.google.com/file/d/1hi1dibkHyFbaxAteLlZJw6r3g9ddd4Lf/view)
conda 환경 만들기
conda create –name MFCC –clone CGCD conda activate MFCC pip install librosa pip install pandas pip install torchmetrics pip install wandb
pip install –upgrade torch torchaudio
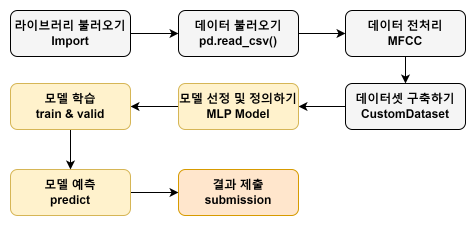
SW중심대학 디지털 경진대회_SW와 생성AI의 만남 : AI부문¶
- 이 AI 경진대회에서는 5초 분량의 오디오 샘플에서 진짜 사람 목소리와 AI가 생성한 가짜 목소리를 정확하게 구분할 수 있는 모델을 개발하는 것이 목표입니다.
- 이 작업은 보안, 사기 감지 및 오디오 처리 기술 향상 등 다양한 분야에서 매우 중요합니다.
- 제공되는 베이스라인 코드에서는 음성 파일에서 MFCC(Mel Frequency Cepstral Coefficients)로 특징을 추출하여 MLP(다층 퍼셉트론) 모델을 학습시키고 추론하는 과정을 포함하고 있으며, MFCC가 아닌 다른 방법론 역시 충분히 적용해볼 수 있습니다.
# -*- coding: utf-8 -*-
"""baseline.ipynb
Automatically generated by Colab.
Original file is located at
https://colab.research.google.com/drive/1RUfsEHt4xZAxuzo1zWplSevA-1IRL58M
# Imports
"""
모델 학습 및 추론에 사용할 라이브러리들을 불러옵니다.
"""
# Import(https://pbl-viewer-lite.dacon.work/lab/index.html#Import)
모델 학습 및 추론에 사용할 라이브러리들을 불러옵니다.
"""
import librosa
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import random
from torch import nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
import torch
import torchmetrics
import os
import warnings
warnings.filterwarnings('ignore')
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
"""# Config"""
"""
### Config
**1. SR(Sample Rate)**
- 오디오 데이터의 샘플링 레이트를 설정합니다.
- 오디오 데이터의 초당 샘플 수를 정의합니다.
**2.N_MFCC(Number of MFCCs)**
- N_MFCC는 멜 주파수 켑스트럼 계수(MFCCs)의 개수를 의미합니다.
- MFCC는 오디오 신호의 주파수 특성을 인간의 청각 특성에 맞게 변환한 것으로, 음성 인식 등의 분야에서 많이 사용됩니다.
**3. ROOT_FOLDER**
- 데이터셋의 루트 폴더 경로를 설정합니다.
**4. N_CLASSES**
- 분류할 클래스의 수를 설정합니다.
- 모델의 출력 차원을 설정할 때 사용됩니다.
**5. BATCH_SIZE**
- 배치 크기를 설정합니다.
- 학습 시 한 번에 처리할 데이터 샘플의 수를 정의합니다
- 큰 배치 크기는 메모리 사용량을 증가시키지만, 학습 속도를 높입니다.
**6. N_EPOCHS**
- 학습 에폭 수를 설정합니다.
- 전체 데이터셋을 학습할 횟수를 정의합니다.
- 에폭 수가 너무 적으면 과소적합이 발생할 수 있고, 너무 많으면 과적합이 발생할 수 있습니다.
**7. LR (Learning Rate)**
- 학습률을 설정합니다.
- 모델의 가중치를 업데이트할 때 사용되는 학습 속도를 정의합니다.
- 학습률이 너무 크면 학습이 불안정해질 수 있고, 너무 작으면 학습 속도가 느려집니다.
**8. SEED**
- 재현성을 위해 SEED값을 고정하는 SEED를 설정해줍니다. %% %% %%
"""
class Config:
SR = 32000
N_MFCC = 13
# Dataset
ROOT_FOLDER = './'
# Training
N_CLASSES = 2
BATCH_SIZE = 96
N_EPOCHS = 5
LR = 3e-4
# Others
SEED = 42
CONFIG = Config()
"""
### Fixed RandomSeed[](https://pbl-viewer-lite.dacon.work/lab/index.html#Fixed-RandomSeed)
- 아래의 코드는 머신러닝이나 딥러닝 모델을 훈련할 때, 결과의 재현성을 보장하기 위해 사용되는 함수입니다.
- 이 함수는 다양한 랜덤 시드를 고정하여, 실행할 때마다 동일한 결과를 얻기 위해 사용됩니다.
"""
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(CONFIG.SEED) # Seed 고정
"""
### Train & Validation Split[](https://pbl-viewer-lite.dacon.work/lab/index.html#Train-&-Validation-Split)
여기서는 인공지능 모델 학습에서 중요한 데이터 전처리를 수행합니다.
모델을 훈련하기 전에, 전체 데이터 세트를 두 개의 서브셋으로 나눠줍니다.
하나는 모델 학습에 사용되는 학습 데이터 세트이고, 다른 하나는 학습된 모델의 성능을 평가하기 위한 검증 데이터 세트입니다.
이렇게 데이터를 분할하는 이유는 모델이 새로운 데이터에 대해 얼마나 잘 일반화하는지 평가하기 위해서입니다.
모델이 훈련 데이터에만 과도하게 최적화되지 않도록 검증 데이터 세트를 사용하여 모델의 성능을 주기적으로 검증합니다.
"""
df = pd.read_csv('./train.csv')
train, val, _, _ = train_test_split(df, df['label'], test_size=0.2, random_state=CONFIG.SEED)
"""## Data Pre-processing : MFCC"""
"""
# Data Pre-processing : MFCC[¶](https://pbl-viewer-lite.dacon.work/lab/index.html#Data-Pre-processing-:-MFCC)
- 이 코드는 MRCC 특징을 추출하고, 이를 학습에 사용할 형식으로 변환하는 함수를 정의하는 코드입니다.
- `librosa.load`를 사용하여 `row['path']`에 해당하는 오디오 파일을 로드합니다.
- 샘플링 레이트는 CONFIG.SR로 지정됩니다.
- `librosa.feature.mfcc`를 사용하여 오디오 신호 y로부터 MFCC 특징을 추출합니다.
- `CONFIG.N_MFCC`는 추출할 MFCC 계수의 개수를 지정합니다.
-
- 추출된 MFCC는 프레임별로 계산되므로, 각 프레임의 평균값을 구하여 전체 파일에 대한 MFCC 특징을 대표하는 벡터를 얻습니다.
- `train_mode = True`인 경우, 현재 행의 레이블을 읽어와 CONFIG.N_CLASSES 길이의 벡터로 변환합니다.
- 레이블이 'fake'이면 첫 번째 원소를 1로, 'real'이면 두 번째 원소를 1로 설정합니다.
- 이 벡터를 labels 리스트에 추가합니다.
"""
def get_mfcc_feature(df, train_mode=True):
features = []
labels = []
for _, row in tqdm(df.iterrows()):
# librosa패키지를 사용하여 wav 파일 load
y, sr = librosa.load(row['path'], sr=CONFIG.SR)
# librosa패키지를 사용하여 mfcc 추출
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=CONFIG.N_MFCC)
mfcc = np.mean(mfcc.T, axis=0)
features.append(mfcc)
if train_mode:
label = row['label']
label_vector = np.zeros(CONFIG.N_CLASSES, dtype=float)
label_vector[0 if label == 'fake' else 1] = 1
labels.append(label_vector)
if train_mode:
return features, labels
return features
train_mfcc, train_labels = get_mfcc_feature(train, True)
val_mfcc, val_labels = get_mfcc_feature(val, True)
"""# Dataset"""
class CustomDataset(Dataset):
def __init__(self, mfcc, label):
self.mfcc = mfcc
self.label = label
def __len__(self):
return len(self.mfcc)
def __getitem__(self, index):
if self.label is not None:
return self.mfcc[index], self.label[index]
return self.mfcc[index]
train_dataset = CustomDataset(train_mfcc, train_labels)
val_dataset = CustomDataset(val_mfcc, val_labels)
train_loader = DataLoader(
train_dataset,
batch_size=CONFIG.BATCH_SIZE,
shuffle=True
)
val_loader = DataLoader(
val_dataset,
batch_size=CONFIG.BATCH_SIZE,
shuffle=False
)
"""# Define Model"""
"""
### Define Model[](https://pbl-viewer-lite.dacon.work/lab/index.html#Define-Model)
- `MLP()` 클래스는 PyTorch의 nn.Module을 상속받아 정의된 Multilayer Perceptron 모델입니다.
**1. `__init__`메서드**
- 모델의 각 구성요소를 초기화 합니다.
- `input_dim=CONFIG.N_MFCC` : MFCC의 개수를 의미합니다.
- `hidden_dim` : 은닉층의 차원 수입니다.
- `output_dim` : 분류할 클래스의 수를 의미합니다.
**2. `__forward__` 메서드**
- `forward` 메서드는 입력 데이터를 순차적으로 세 개의 선형 계층과 ReLU 활성화 함수를 거쳐 최종적으로 시그모이드 함수를 적용하여 출력 확률을 계산합니다.
"""
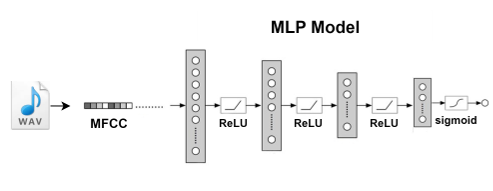
class MLP(nn.Module):
def __init__(self, input_dim=CONFIG.N_MFCC, hidden_dim=128, output_dim=CONFIG.N_CLASSES):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
x = torch.sigmoid(x)
return x
"""# Train & Validation"""
"""
### Train & Validation[¶](https://pbl-viewer-lite.dacon.work/lab/index.html#Train-&-Validation)
아래의 코드는 PyTorch를 사용한 딥러닝 모델의 훈련 및 검증 과정과 다중 레이블 AUC 점수 계산을 포함합니다.
"""
from sklearn.metrics import roc_auc_score
def train(model, optimizer, train_loader, val_loader, device):
model.to(device)
criterion = nn.BCELoss().to(device)
best_val_score = 0
best_model = None
for epoch in range(1, CONFIG.N_EPOCHS+1):
model.train()
train_loss = []
for features, labels in tqdm(iter(train_loader)):
features = features.float().to(device)
labels = labels.float().to(device)
optimizer.zero_grad()
output = model(features)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
_val_loss, _val_score = validation(model, criterion, val_loader, device)
_train_loss = np.mean(train_loss)
print(f'Epoch [{epoch}], Train Loss : [{_train_loss:.5f}] Val Loss : [{_val_loss:.5f}] Val AUC : [{_val_score:.5f}]')
if best_val_score < _val_score:
best_val_score = _val_score
best_model = model
return best_model
def multiLabel_AUC(y_true, y_scores):
auc_scores = []
for i in range(y_true.shape[1]):
auc = roc_auc_score(y_true[:, i], y_scores[:, i])
auc_scores.append(auc)
mean_auc_score = np.mean(auc_scores)
return mean_auc_score
def validation(model, criterion, val_loader, device):
model.eval()
val_loss, all_labels, all_probs = [], [], []
with torch.no_grad():
for features, labels in tqdm(iter(val_loader)):
features = features.float().to(device)
labels = labels.float().to(device)
probs = model(features)
loss = criterion(probs, labels)
val_loss.append(loss.item())
all_labels.append(labels.cpu().numpy())
all_probs.append(probs.cpu().numpy())
_val_loss = np.mean(val_loss)
all_labels = np.concatenate(all_labels, axis=0)
all_probs = np.concatenate(all_probs, axis=0)
# Calculate AUC score
auc_score = multiLabel_AUC(all_labels, all_probs)
return _val_loss, auc_score
"""## Run"""
"""
### Run[](https://pbl-viewer-lite.dacon.work/lab/index.html#Run)
모델을 초기화하고, 옵티마이저를 설정한 다음 모델 훈련 함수를 호출하여 실제로 훈련 과정을 실행하는 단계입니다.
"""
model = MLP()
optimizer = torch.optim.Adam(params = model.parameters(), lr = CONFIG.LR)
infer_model = train(model, optimizer, train_loader, val_loader, device)
"""## Inference"""
test = pd.read_csv('./test.csv')
test_mfcc = get_mfcc_feature(test, False)
test_dataset = CustomDataset(test_mfcc, None)
test_loader = DataLoader(
test_dataset,
batch_size=CONFIG.BATCH_SIZE,
shuffle=False
)
def inference(model, test_loader, device):
model.to(device)
model.eval()
predictions = []
with torch.no_grad():
for features in tqdm(iter(test_loader)):
features = features.float().to(device)
probs = model(features)
probs = probs.cpu().detach().numpy()
predictions += probs.tolist()
return predictions
preds = inference(infer_model, test_loader, device)
"""## Submission"""
submit = pd.read_csv('./sample_submission.csv')
submit.iloc[:, 1:] = preds
submit.head()
submit.to_csv('./baseline_submit.csv', index=False)
데이터 증강.
background data는
https://research.google.com/audioset/download.html 여기서 다운받음.
https://github.com/audioset/ontology/blob/master/ontology.json
여기서 masking도 함.
https://research.google/pubs/audio-set-an-ontology-and-human-labeled-dataset-for-audio-events/
dataset 설명인듯!
1시간에 240개, 24시간에 5780
댓글남기기