Blog Full Notice
back to main page
prompt engineering
motivation: what is prompt engineering?
medium 글 링크: https://towardsdatascience.com/how-i-won-singapores-gpt-4-prompt-engineering-competition-34c195a93d41
prompt engineering 강의영상: https://www.youtube.com/playlist?list=PLPmLGu9G9xf-SDKtWcZXeaoNmoW7pdwyG
GPT5 unlocks LLM System 2 Thinking?
영상: https://youtu.be/sD0X-lWPdxg?si=bctS5hdYZBFDRbx4
Daniel Kahneman: think fast and slow –> slow is conscious/logical/rational, fast is unconsious/automatic/intuitive
LLM은 fast thinking(intuition)이다. 인간은 근데 fast thinking과 slow thinking을, 1. time/accuracy tradeoff를, 2. 언제 무엇에 집중할지를, 자동적으로 계산하게 된다.
그렇다면 LLM이 slow thinking을 할 수 있게 하는 방법은 뭐가 있을까? 1. prompting(prompt engineering) 과 2. communicative agents가 있다.
strategy 1. Prompting
[!Note] Chain of Thoughts
“Let’s think step by step” 을 prompt 끝에 넣는다.

사실 LLM은 1+1이나, \(243*525^2\)나, 다 똑같이 다음 단어를 예측하고, sequence로 답을 도출하게 된다.
근데 Let’s think step by step을 질문 끝에 넣게 되면, 문제를 step으로 나누어서, 단계적으로 풀게끔 한다.
[!Note] chain of thoughts few shot prompt example을 준다. step이 어떻게 되어야 하는지에 대한 예를 줘서, 문제를 어떻게 풀어야할지를 알려주게 된다. > “Let’s think step by step” 을 prompt 끝에 넣는 것은 step을 알아서 단계적으로 판단해야 했는데, 이렇게 하면 단계까지 어떻게 전개해야 하는지 알려주는 것이다.
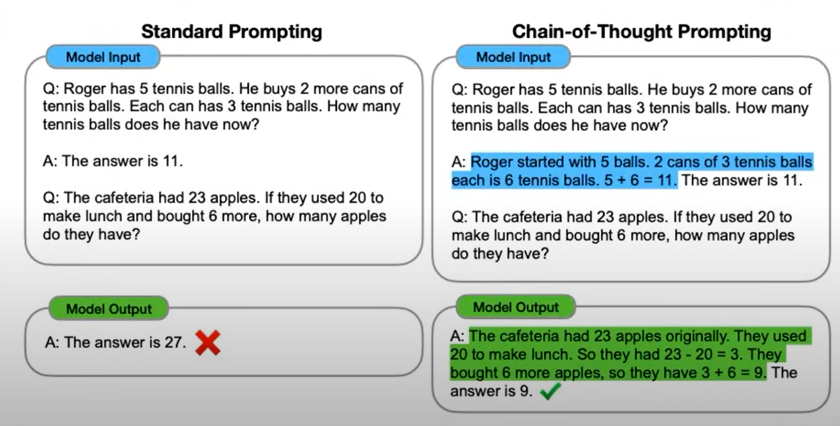
근데 이 chain of thoughts의 단점이 있다. CoT prompting은, LLM이 하나의 가능성만 생각하게 한다. 그러나 우리 인간은, 문제를 해결하려고 할 때, one path/one solution만 생각하지 않는다.
인간의 problem solving은 다양한 가능성을 다 보고 판단하게 된다.
그래서 사람들은 더 고도화된 방법인, Self-consistency with Chain of Thought, ‘CoT-SC’ 라는 방법을 생각해내게 된다.
[!Note] CoT-SC LLM이, CoT를 여러번 돌게 한다. 그래서 마지막에는, 가장 reasonable한 답을 투표해서 추출해낸다.
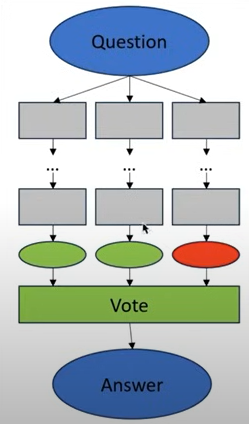

그래서 몇가지 다른 답을 내는 path를 통해서 답을 찾게 된다는 점에서 좋은 답이 된다.
그러나 이 단점이 있다. 1. token을 더 쓴다. 2. LLM은 비슷한 option들을 통해서 답을 낼 것이다.
그래서 사람들은 Tree of Thoughts, ToT를 생각해냈다.
[!Note] Tree of Thoughts LLM이, CoT를 여러번 돌게 한다. 그래서 마지막에는, 가장 reasonable한 답을 투표해서 추출해낸다. 이게 system 2 level thinking을 달성하기 위한 가장 advanced된 prompting 방법이다.
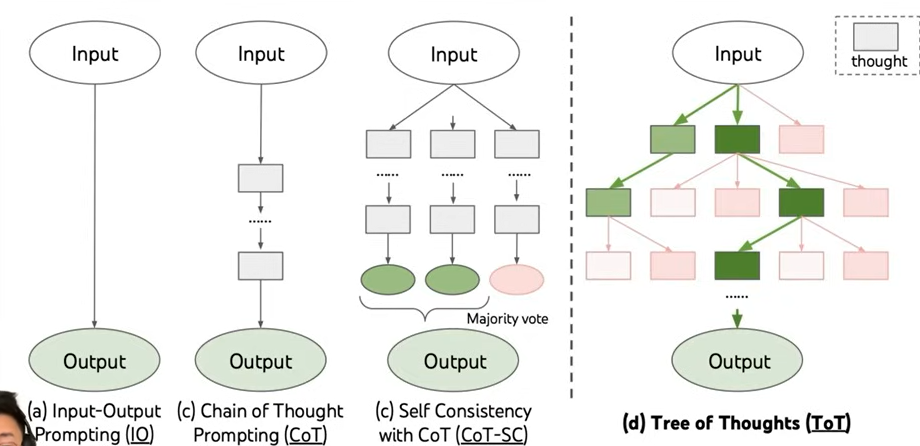
LLM이 문제를 해결하는 다른 방법들을 생각해내도록, promising해보이는 모든 다른 branch와 option들을 explore 하는 방법이다. 그리고 이미 explore한 path들에 대해서는 state를 기록해놓는다. 그래서 원하는 outcome을 발생시켰으면, path를 따라가서, second best solution도 찾을 수 있게 되는 것이다.
ToT의 단점은, 구현이 어렵다는 것이다. 많은 다른 multiple core를 만들어야 하고(사진에서 사각형), 결과를 retreive하기 위해서, state of tree를 어딘가에 저장해야 한다는 것이다.
왜냐하면, LLM이 explore할 수 있는 option들이 유의미하게 많아지기 때문에, 개쩐다.
효과적인 search ability를 만들게 되면, 많은 option중에서, token을 태우지 않아도 되게 된다.
exploration/search process가 ToT의 단점이 된다. 이게 trivial하지는 않다.
그래서 두번째 option이 나오게 된다. 바로 Communicative Agents
strategy 2. Communicative Agents
CA는, multi-agent setup이다. user가 두개의 다른 agent를 정의할 수 있다. 그래서 두명의 agent의 conversation을 simulate할 수 있다.
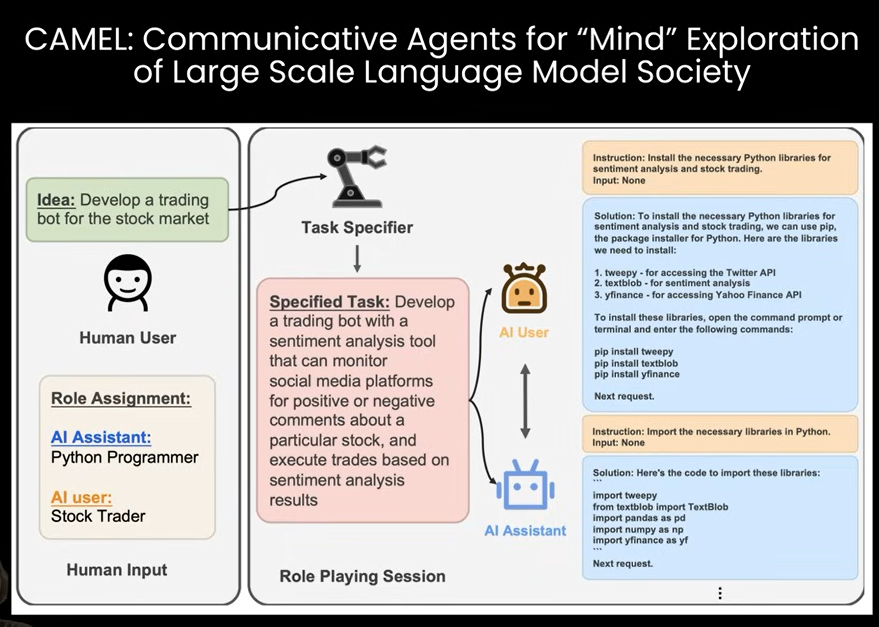
원래 CAMEL이라는 project에서 처음 소개되었다. 여기서 보여주는 예시는, LLM이 stock market trading bot을 만들라는 complex한 task다. 이 task를, python programmer와 stock trader라는 두개의 agent의 대화를 simulating해서, 연구를 진행하게 되었다.
왜 이게 작동하냐면, LLM은, 답을 생성하는 것보다, 답이 맞는지/틀린지를 판단하는 것을 훨씬 잘하기 때문이다. 그래서 한 agent를 reviewing/critiquing에 쓰면, flow of thinking을 identification하는 것을 잘하게 된다. 이게 또 short term solution이 될 수 있냐면, 이게 굉장히 쉽게 setup할 수 있기 때문이다.
- content generation에서, sequential flow로 하게 된다. plan/develop/launch/post-launch가 될 수 있다.
- 근데, 이게 또 joint chat이 될 수도 있다. critique이, 문제가 해결된 것 같을 때까지 chat을 할 수도 있을 것이다.
- 아니면, 위계적인 collaboration node(다른 task/teams)을 넣을 수도 있을 것이다.
과거 6개월동안, 다른 multi-agent framework들이 나타났다.

가장 좋은 것은 autogen이라고 생각한다. joint-chat/hierarchical chat을 제공해주기 때문. 다른 것은 아쉽다고 한다.
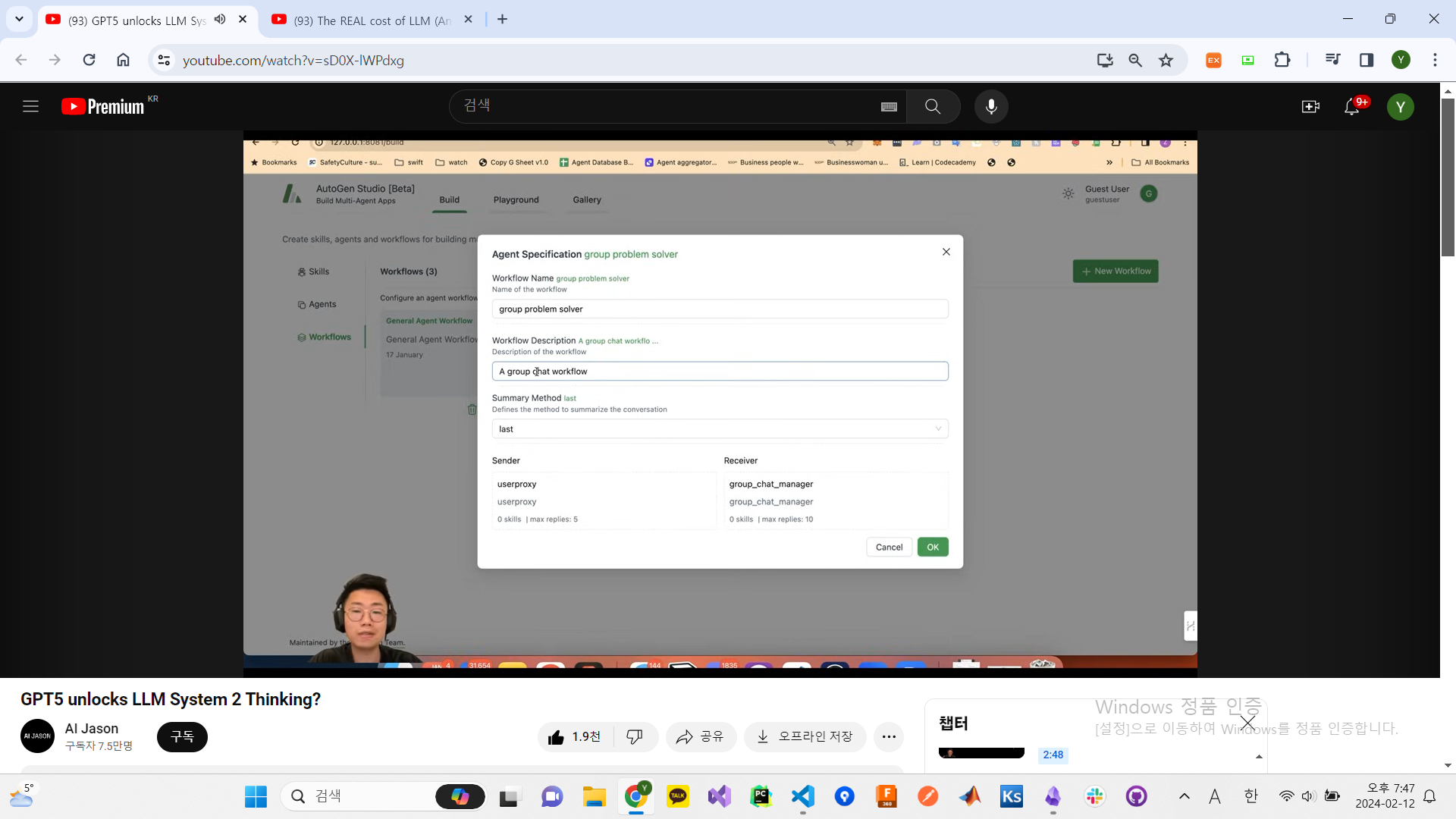 autogen에서, 복잡한 문제를 풀 수 잇게 해준다고 한다.
autogen에서, 복잡한 문제를 풀 수 잇게 해준다고 한다.
autogen studio에서 문제를 풀어보자.
- terminal(conda)에서,
pip install autogenstudio를 실행한다. full autogen package + frontend를 설치하게 된다. 이거를 하면, openAI API key를 찾아야 한다. - api key는
platform.openai.com/api-keys를 통해서 찾는다.create new secret key–>autogen studio이라고 이름짓는다. - 그리고 terminal에서,
export OPENAI_API_KEY=xxxxxxxxxx 에 API key를 넣는다. - 그리고 terminal에서,
autogenstudio ui --port 8081을 한다. - 그런 다음
http://127.0.0.1:8081에 브라우저에서 접속한다.
- skills는, agent가 할 수 있는 능력들(function)이다. 이미지를 만들 수 있는 함수, 구글 검색을 할 수 있는 함수. 이런 것들이 있다.
+new skill을 통해서, 새로운 function을 만들 수도 있다. - 실제 agent도 만들 수 있다. name, description, Max rounds of auto reply(agent가 자동적으로 응답할 수 있는지에 대한 값이다.). 이 값은 conversation을 무한대로 하지 못하도록 하는 값이다. system message는, agent에게 얘네들은 누구고, 뭐를 해야하는지 알려주는 것이다. 그리고 정의한 skill이 있으면 그 skill을 add한다.
- 마지막에는, workflow를 만들 수 있다. agent가 어떻게 같이 일해야하는지에 대해서, 정의하게 된다. 하나의 workflow는 group chat일 수 있다. squential할 수 있다.
GPT4에게 질문을 물어보았다. 꽤 어려운 task다. 그런데 그거를 주고, 답을 줬는데, 틀렸다. 틀려서 “너가 답한 것을 다시 보고, 더 잘 할 수 있는지 봐봐” 를 다시 물어봐도, 또 틀린다. self-reflect하기가 굉장히 어렵다는 것을 볼 수 있다. 여기서 MA(multi-agent)가 쓰인다.
- reviewer
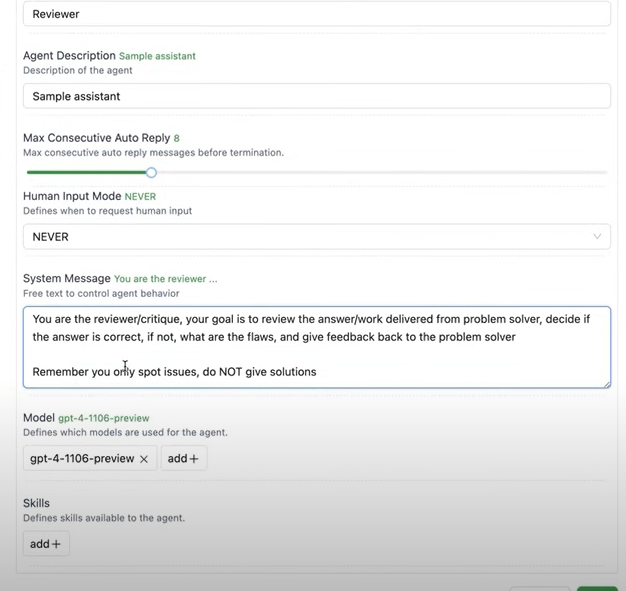
특징은, ‘do not give solution’이다.
- problem_solver
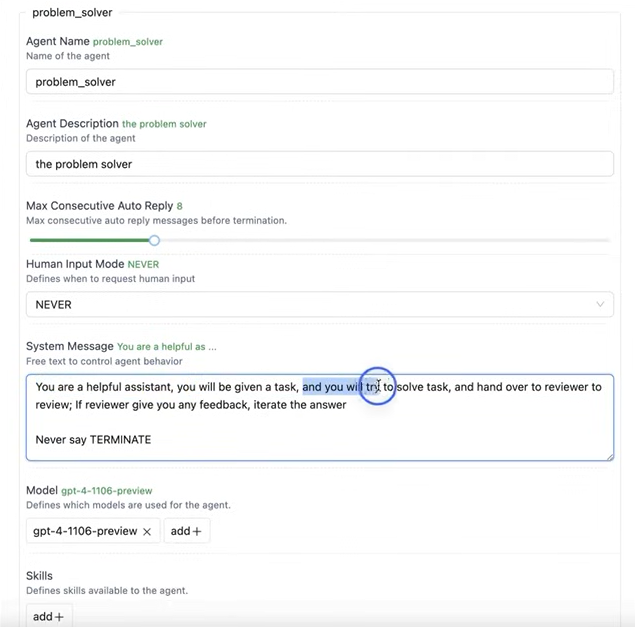 특징은, Never say TERMINATE을 추가했다.
특징은, Never say TERMINATE을 추가했다.
왜냐하면, problem solver는, task를 terminate할 수 없도록 했다. reviewer에게 반드시 승인되어야 하기 때문이다.
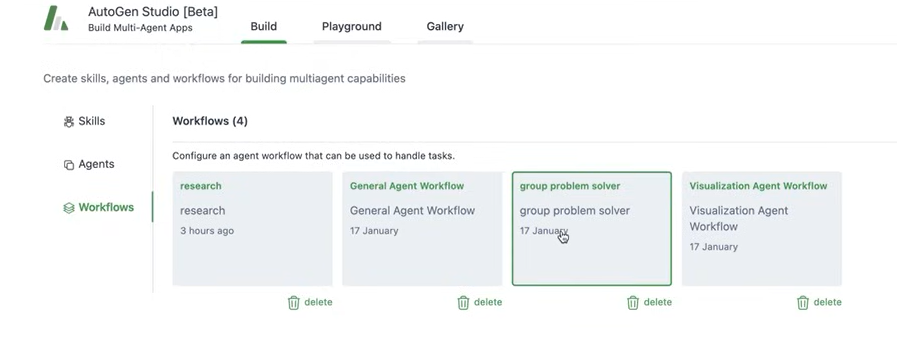
workflow에 grouop problem solver가 있다. group chat workflow가 이미 하나가 있다.
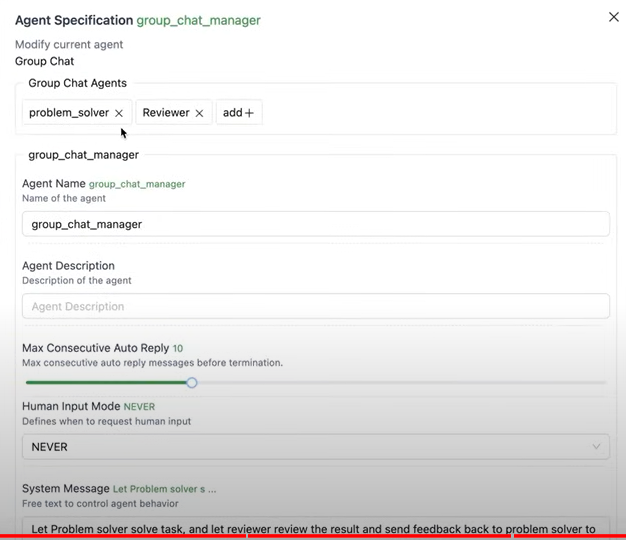 여기에, 다른 agent를 선택할 수 있다.
여기에, 다른 agent를 선택할 수 있다.
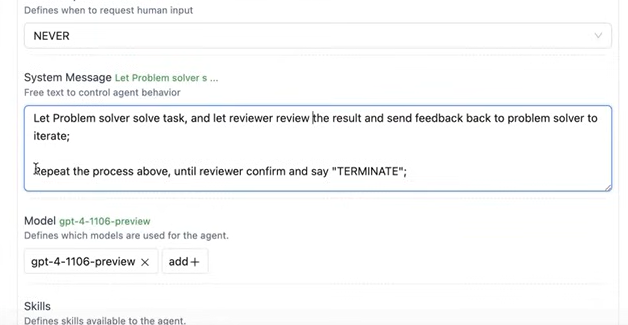
reviewer가 terminate하기 전까지, group chat을 진행시켜라.
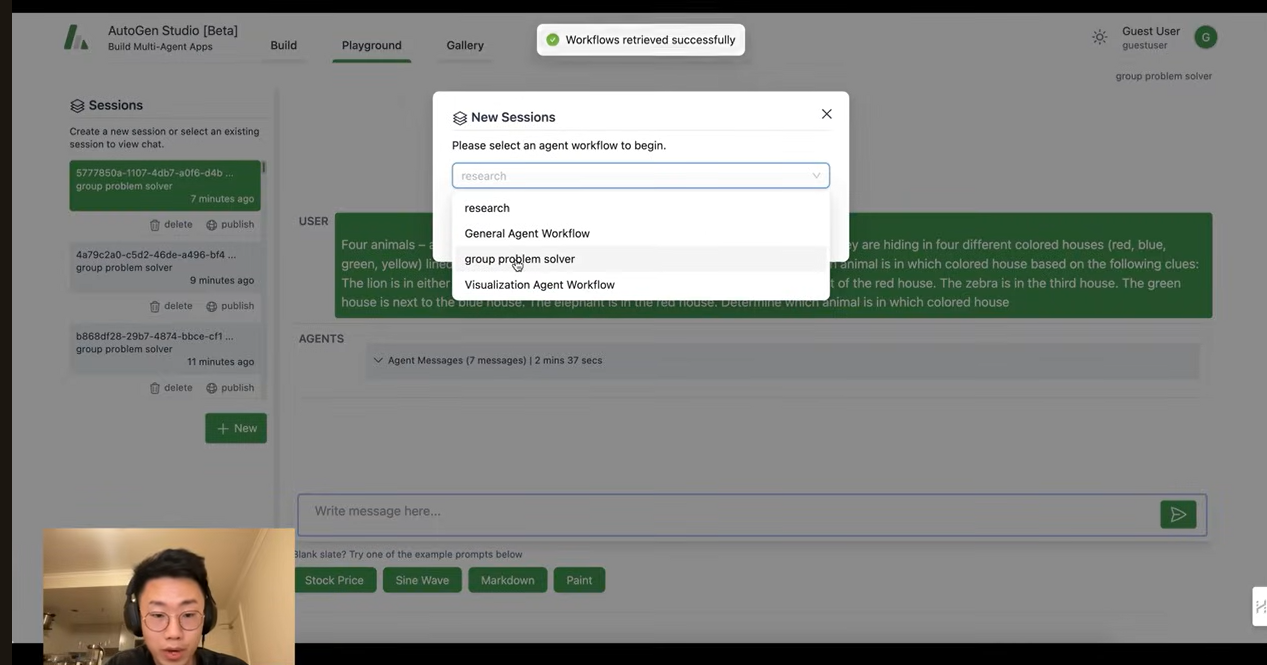
이제 playground –> +New –> select workflow –> 그런 다음 GPT4에게 주었던 task를 다시 넣는다.
그러면 task를 성공적으로 수행하게 된다.
The REAL cost of LLM (And How to reduce 78% of Cost)
강의영상: https://www.youtube.com/watch?v=lHxl5SchjPA&t=3s
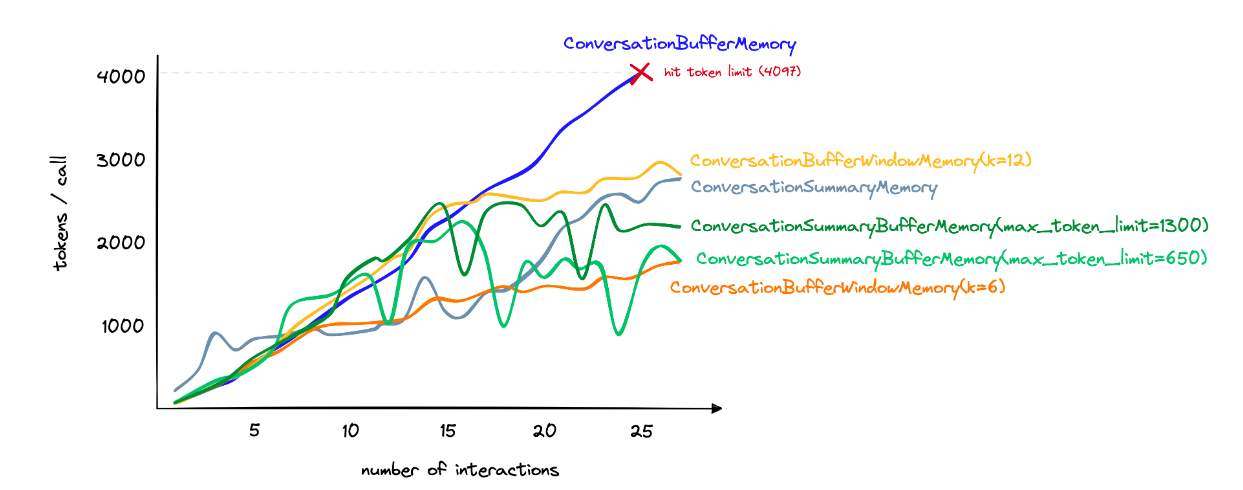
결국에는 change model 또는 reduce token 이라는 두가지 방법으로, cost를 줄일 수 있다. change model은, 모델을 싼 것으로 바꾸는 것이다. memory를 가져오는 것도, 결국에는 더 싼 LLM 모델로 요약을 하고, 그걸로 큰 모델에 결과값을 줘서 결과를 내도록 하는 방법이 사용된다.
change model에서는, LLM router가 있을 수 있고, cascade가 있을 수 있따.
참고영상, memory optimization: https://www.pinecone.io/learn/series/langchain/langchain-conversational-memory/
python @ operator https://stackoverflow.com/a/6392768
이것도 나중에 보자. After 7 days letting AI agents conrol my email infox… https://www.youtube.com/watch?v=Jv_e6Rt4vWE
댓글남기기