Blog Full Notice
back to main page
나만의 GPT를 만들어보자!
motivation: transformer와 pytorch workflow를 이해하기 위해서 나만의 GPT를 만들어보자!
강의영상: Let’s build GPT: from scratch, in code, spelled out.
Andrej Karpathy가 2023년 1월에 만든 영상인 Let's build GPT: from scratch, in code, spelled out. 통해, transformer를 더 이해하고, pytorch workflow를 더 이해해 보려고 한다.
0. objectives
tiny sheakspeare dataset을 통해서, 한 character씩 출력하는 GPT를 만들어보려고 한다.
1. read and explore the data
1. download tiny shakespeare dataset
!wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/inpu.txt
2. open the text file
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
3. print length of characters in text file and check the text
print("length of dataset in characters: ", len(text))
print(text[:1000])
4. dataset에서 unique한 word 확인하는 방법
chars = sorted(list(set(text))) # 전체 dataset에서 유일한 character들의 list
vocab_size = len(chars)
print(''.join(chars))
print(vocab_size) # 65
2. tokenization-raw string(character)을 sequence of integer로 바꾸기 위해서.
1. string을 token으로 바꾸어주는 것.
# create a mapping from characters to integers
stoi = {ch: i for i, ch in enumerate(chars)}
itos = {i: ch for i, ch in enumerate(chars)}
encode = lambda s: [stoi[c] for c in s] # encoder는 string을 받아서, 그 token(여기서는 한개의 character)에 해당하는 integer들의 list를 return한다.
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: integer의 list를 받아서, string을 출력한다.
print(encode("hii there"))
print(decode(endcode("hii there")))
# 를 하게 되면, list의 integer를, 다시 hi there로 바꾸어준다.
tokenizer는, 많은 다른 방법들이 있다. 구글은 text to integer 스키마를 sentencepiece를 쓴다.
SentencePiece는 sub-word units(tokens)를 사용하는데, 하나의 단어 전부를 encoding하는 것이 아니라, 또 각각의 character를 encoding하는 것은 또 아니다. sub-word unit level이다. openAI는, tiktoken 이라는 라이브러리가 있는데, 이거는 BPE(byte pair encoding tokenizer)인데, 이거는 실제 GPT 에서 사용되고 있는 방법이다.
import tiktoken
enc = tiktoken.get_encoding("hii there") # 이런 식으로 list of tokens를 받을 수 있다. 3개의 개수의 list가 나온다.
assert enc.decode(enc.encode("hello world")) == "hello world"
enc.n_vocab # 50257 개의 token을 가진다.
# To get the tokeniser corresponding to a specific model in the OpenAI API:
enc = tiktoken.encoding_for_model("gpt-4")
결국 small codebook size <–> long sequence list large vocabulary size <–> short sequence list ([43, 2, 5])
이렇게 된다. 보통 sub-word encoding을 사용하는데, 안드레는 간단하게 하고 싶어서 character level tokenize한다고 한다.
2. shakespeare의 모든 data를 tokenize하자.
import torch
data = torch.tensor(encode(text), dtype=torch.long) # 모든 text를 encoding해서, tensor에 넣겠다.
print(data.shape, data.dtype) # torch.Size([1115394]) torch.int64
print(data[:1000]) # 1000개의 sequence를 보자.
3. train/validation split을 하자. 9:1로. (overfitting을 막기 위해서, 즉 정확히 90%의 data처럼 결과가 나오지 않도록.)
n = int(0.9*len(data))
train_data = data[:n]
val_data = data[n:]
3. data loader -> batches of chunks of data
text/integer sequences 를 transformer에 넣어서, pattern을 배울 수 있도록 하자.
이때, transformer에 한번에 넣지 않을 것이다. 우리는 datset의 chuck들로 넣을 것이다. 이런 chunk들은, maximum length를 가진다. maximum length를, block_size라고 한다.
1. maximum length를 8로 정하자.
block_size = 8
train_data[:block_size + 1] # sequence 안에 있는 처음 9개 문자
2. transformer가 block_size 그 이상의 context를 갖지 못하도록 한다.
x = train_data[:block_size] # transformer의 input
y = train_data[1:block_size+1] # 다음 block_size 크기를 가지는 train_data
for t in range(block_size):
context = x[:t+1]
target = y[t]
print(f"when input is {context} the target: {target}")
``` output text when input is tensor([18]) the target: 47 when input is tensor([18, 47]) the target: 56 when input is tensor([18, 47, 56]) the target: 57 when input is tensor([18, 47, 56, 57]) the target: 58 when input is tensor([18, 47, 56, 57, 58]) the target: 1 when input is tensor([18, 47, 56, 57, 58, 1]) the target: 15 when input is tensor([18, 47, 56, 57, 58, 1, 15]) the target: 47 when input is tensor([18, 47, 56, 57, 58, 1, 15, 47]) the target: 58
## 3. batch dimension을 맞춰야 한다.
chuncks of text를 sampling 할 때, transformer에 feed하기 전에, mutiple chuncks of text의 mini-batch가 하나의 tensor에 있게 된다.
이렇게 하는 이유는, 병렬화를 하기 위함이다. 효율적으로 하기 위해서 병렬화 하기 위해서, 이 chunk는 독립적으로 수행되게 된다.
``` python
torch.manual_seed(1337)
batch_size = 4 # 병렬적으로 돌릴 독립적인 8개의 글자
block_size = 8 # maximum context length (8개의 글자)
def get_batch(split):
data = train_data if split == 'train' else val_data # split이 training split이면 train_data를 볼 것이다.
ix = torch.randint(len(data) - block_size, (batch_size,) ) # batch_size(4) 개의, (0, 100000 - 8) 사이의 숫자 중에서, (4,) 처럼 data가 나오게 한다.
x = torch.stack([data[i: i+block_size] for i in ix]) # i 번째에서 시작하는 starting block
y = torch.stack([data[i+1 : i+block_size+1]for i in ix]) # x 다음 1개 이후에 나오는 8개의 character로 이루어진 sequence.
return x, y # x, y는 4*8 tensor가 된다.
xb, yb = get_batch('train')
print('inputs:')
print(xb.shape) # torch.Size([4,8])
print(xb)
print('targets:')
print(yb.shape)
print(yb)
print('----')
for b in range(batch_size): # batch dimension
for t in range(block_size): # time dimension
context = xb[b, :t+1]
target = yb[b,t]
print(f"when input is {context.tolist()} the target: {target}")
``` text output inputs: torch.Size([4, 8]) tensor([[24, 43, 58, 5, 57, 1, 46, 43], [44, 53, 56, 1, 58, 46, 39, 58], [52, 58, 1, 58, 46, 39, 58, 1], [25, 17, 27, 10, 0, 21, 1, 54]]) targets: torch.Size([4, 8]) tensor([[43, 58, 5, 57, 1, 46, 43, 39], [53, 56, 1, 58, 46, 39, 58, 1], [58, 1, 58, 46, 39, 58, 1, 46], [17, 27, 10, 0, 21, 1, 54, 39]]) —- when input is [24] the target: 43 when input is [24, 43] the target: 58 when input is [24, 43, 58] the target: 5 when input is [24, 43, 58, 5] the target: 57 when input is [24, 43, 58, 5, 57] the target: 1 when input is [24, 43, 58, 5, 57, 1] the target: 46 when input is [24, 43, 58, 5, 57, 1, 46] the target: 43 when input is [24, 43, 58, 5, 57, 1, 46, 43] the target: 39 when input is [44] the target: 53 when input is [44, 53] the target: 56 when input is [44, 53, 56] the target: 1 when input is [44, 53, 56, 1] the target: 58 when input is [44, 53, 56, 1, 58] the target: 46 when input is [44, 53, 56, 1, 58, 46] the target: 39 when input is [44, 53, 56, 1, 58, 46, 39] the target: 58 when input is [44, 53, 56, 1, 58, 46, 39, 58] the target: 1 when input is [52] the target: 58 when input is [52, 58] the target: 1 when input is [52, 58, 1] the target: 58 when input is [52, 58, 1, 58] the target: 46 when input is [52, 58, 1, 58, 46] the target: 39 when input is [52, 58, 1, 58, 46, 39] the target: 58 when input is [52, 58, 1, 58, 46, 39, 58] the target: 1 when input is [52, 58, 1, 58, 46, 39, 58, 1] the target: 46 when input is [25] the target: 17 when input is [25, 17] the target: 27 when input is [25, 17, 27] the target: 10 when input is [25, 17, 27, 10] the target: 0 when input is [25, 17, 27, 10, 0] the target: 21 when input is [25, 17, 27, 10, 0, 21] the target: 1 when input is [25, 17, 27, 10, 0, 21, 1] the target: 54 when input is [25, 17, 27, 10, 0, 21, 1, 54] the target: 39
결과가 이렇게 나오는데, 결국 y가 transformer의 마지막에서, loss를 계산하게 만드는 것이 된다.
# 4. baseline: bigram LM, loss, generation
이제 xb, transformer에 feed할 batch of inputs가 있게 되면,
``` text
tensor([[24, 43, 58, 5, 57, 1, 46, 43],
[44, 53, 56, 1, 58, 46, 39, 58],
[52, 58, 1, 58, 46, 39, 58, 1],
[25, 17, 27, 10, 0, 21, 1, 54]])
이거를 이제 NN에 feed해보자.
LM에서 가장 간단한 NN인 BiGram 모델로 시작하자.
bigram pytorch model
import torch
import torch.nn as nn
from torch.nn import functional as F
torch.manual_seed(1337)
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size) # shape of row, col
def forward(self, idx, targets=None): # index, input x == idx
# idx and targets are both (B,T) tensor of integers
logits = self.token_embedding_table(idx) # (B,T,C) == (4,8,65) # 여기서 channel은 token을 몇차원의 벡터로 나타낼 것인지에 대해서, 그 벡터의 차원이 되는 것. 자세한 설명은 아래에.
if targets is None: # generate에서 self(idx)만 할 수 있게끔
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T,C) # CE API에 맞추기 위해서. C가 두번쨰 차원으로 나와야 하기 때문이다.
tartgets = targets.view(-1) # targets.view(B*T)와 같은 효과.
loss = F.cross_entropy(logits, targets) # loss는 prediction(logits)와 targets와의 CE다.
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B,T) array of indices in the current context
for _ in range(max_new_tokens):
# get the predictions
logits, loss = self(idx)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B,C)
# apply softmax to get probabilites
probs = F.softmax(logits, dim=-1) # (B,C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B,1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
m = BigramLanguageModel(vocab_size)
logits, loss = m(xb, yb)
print(logits.shape)
print(loss)
idx = torch.zeros((1,1), dtype=torch.long) # zero는 newline character다. 그래서 sequence의 첫번째 character로 넣을 만 한 것 같다.
# 또 idx의 차원을 1,1로 함으로써, B가 1, T(train of tokens)가 1 차원이 된다. 이 말은, sequence가 1개고, 앞으로 token은 추가될 것인데, 결국 sequence가 1개라는 것은 문장이 한개라는 것이다.
print(decode(m.generate(idx, max_new_tokens=100)[0].tolist())) # generate는 batch에서 작용되기 때문에, 하나의 batch를 뽑아내야 한다. 이거는, indexes(tokens)의 list로 만들고, decode 함수로 character로 다시 바꾼다.
을 하면 결과가
torch.Size([32, 65])
tensor(4.8786, grad_fn=<NllLossBackward0>)
SKIcLT;AcELMoTbvZv C?nq-QE33:CJqkOKH-q;:la!oiywkHjgChzbQ?u!3bLIgwevmyFJGUGp
wnYWmnxKWWev-tDqXErVKLgJ
가 나온다. 왜 이렇게 쓰레기 값이 나오냐면, 아직 train을 안했기 때문. train을 하더라도 뒤에 나오겠지만, 뒤의 하나의 character(token)만 보기 떄문에
1. init() 의 nn.Embedding(8,3)에 관한 설명 –> 실제로는 nn.Embedding(vocab_size=65, vocab_size=65)다.
nn.Embedding(1st=8, 2nd=3) 에 관한 설명 embedding_layer = nn.Embedding(num_embeddings=8, embedding_dim=3)
print(embedding_layer.weight)
Parameter containing:
tensor([[-0.1778, -1.9974, -1.2478],
[ 0.0000, 0.0000, 0.0000],
[ 1.0921, 0.0416, -0.7896],
[ 0.0960, -0.6029, 0.3721],
[ 0.2780, -0.4300, -1.9770],
[ 0.0727, 0.5782, -3.2617],
[-0.0173, -0.7092, 0.9121],
[-0.4817, -1.1222, 2.2774]], requires_grad=True)
# 만약에
embedding_layer = nn.Embedding(num_embeddings=8, embedding_dim=3)
tensor = torch.randint(0, 8, (4,8))
embedding_layer(tensor)
# 를 하게 되면, embedding_layer(tensor) 는 예를 들어서 tensor의 값이 7이 들어갔으면, 그 7에 해당하는 것을 [-0.4817, -1.1222, 2.2774] 이거로 바꾸어준다는 뜻.
# 즉 tensor.shape를 하면 (4,8) 인데, 이 (4,8) 차원에서 각각의 정수 값을 3차원(embedding_dim) 차원 벡터 값으로 바꿔서, embedding_layer(tensor)의 shape은 (4,8,3)이 된다는 것이다.
2. forward()의 F.cross_entropy(logits(32(B*T=batch_size * block_size, which is 4*8),65 차원), targets(32차원))
cross entropy pytorch official documentation
지금 상황이, 32개의 row와 65개의 column으로 이루어진 행렬 인 logits와, 32개의 행으로 이루어진 벡터인 targets에서, 계산이 어떻게 되는가?
우선 logits의 첫번째 행에 대해서, 65개의 열벡터값이 있을 텐데, 그것들을 softmax 시킨다.
logits = [2.0, 1.0, 0.1] 라면
- \[e^{2.0}=7.389\]
- \[e^{1.0}=2.718\]
- \[e^{0.1}=1.105\]
따라서, Softmax 계산 결과는 다음과 같습니다:
- 클래스 0의 확률: 7.3897.389+2.718+1.105≈0.6597.389+2.718+1.1057.389≈0.659
- 클래스 1의 확률: 2.7187.389+2.718+1.105≈0.2437.389+2.718+1.1052.718≈0.243
- 클래스 2의 확률: 1.1057.389+2.718+1.105≈0.0997.389+2.718+1.1051.105≈0.099
그리고 실제 클래스가 1이면,
\(Loss = -log(0.243) = 1.414\) 을 하게 된다.
근데 그러면 각 row에 대해서 loss를 구하면, column이 65차원이니깐, 65개의 원소를 가지는 65차원 벡터가 나와야 하지 않는가? 근데
F.cross_entropy(logits, targets)
이 함수는 근데 65차원에 대해서 평균을 내버린다. 그래서 하나의 스칼라 값을 내보낸다. 만약에 스칼라 값이 아니라 각각의 열벡터 차원에 대해서 loss를 구하고 싶다면
F.cross_entropy(logits, targets, reduction='none')
를 하게 되면 65 차원으로 값이 나오게 된다.
3. generate()의 F.softmax(logits, dim=-1)
logits라는 tensor가 B,C 차원이라면, dim=-1은 마지막 차원인 T라는 의미다. (dim=0이 첫번쨰 차원) 그래서 C가 65라면, 65개에 대해서 softmax를 하고, 0~1 사이의 값을 tensor에 넣는다.
4. generate()의 torch.cat
torch.cat( (idx), (idx_next), dim=1 )
지금 이렇게 되어있는 상황이다.
idx의 차원은 (B,T)다. idx_next의 차원은 (B,1)인 상황이다.
여기서 dim=1이 의미하는 것은, 뭘까? 그냥 두번째 차원에 값을 이어붙이겠다는 것이다.
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 0)
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497],
[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 1)
tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,
-1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,
-0.5790, 0.1497]])
5. training the bigram model –> pytorch optimzer, train
# create a PyTorch optimizer
optimizer = torch.optim.adamW(m.parameters(), lr=1e-3) # 작은 모델은 더 작아도 됨.
# xb, yb = get_batch('train')
# 'train' 이면 train data를 활용해서, batch_size 만큼의 batch차원을 가지고, block_size(8) 만큼의 train of data를 가진다. 즉 (batch_size, block_size)의 차원을 가진다. xb는, yb는 그 다음 8개의 character를 나타낸다. x가 'hi my na' 라면, y는 'i my nam'이 된다.
batch_size = 32
for stops in range(100):
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = m(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
print(loss.item()) # loss는 하나의 스칼라값이 나오게 된다.
4.7에서 4.5로 줄어든다. 계속 range를 10000 번을 하게 되면, loss가 2.5로 줄어든다.
print(decode(m.generate(idx = torch.zeros((1,1), dtype=torch.long), max_new_tokens=100)[0].tolist()))
이거를 하게 되면,
 그래도 좀 어느정도 합리적인 것처럼 보이는 것이 출력된다.
그래도 좀 어느정도 합리적인 것처럼 보이는 것이 출력된다.
이게 가장 간단한 모델이다. 지금은 token이 서로 대화하고 있지 않아서, 간단한 모델이다.
6. port our code to a script
하나의 product로 만들기 위해서, script를 만들었다.
# 추가한 것.
# 1. hyperparamters 맨 앞에 정의
# 2. device agnostic code. gpu에서 프로그래밍 하기 위해서, 1. 맨 처음에 device = "cuda" 를 해놓고, 2. m = model(...) m = m.to(device) 를 통해서 모델도 gpu로 이동시키고, 3. 모델 내에서, data를 load 시킬 때(get_batch 함수 내에서), x,y = x.to(device), y.to(device) 를 통해서, device(cuda)로 data를 이동시킨다. 그래서 모든 계산이 gpu에서 일어나게 된다. 4. print(decode(m.generate(context = torch.zeros((1,1), dtype=torch.long, device=device), max_new_tokens=500)[0].tolist())) 를 통해서, context tensor를 device에서 만들도록 했다.
# 3. training loop에서, loss.item()을 print했다. 근데 이거는 각각의 batch마다 more/less lucky하기 때문에, current loss의 noisy measurement다. 그래서, estimate_loss라는 함수를 정의했다.
import torch
import torch.nn as nn
from torch.nn import functional as F
# 0. hyper parameters and device agnostic code
batch_size = 32
block_size = 8
max_iters = 3000
eval_interval = 300
learning rate = 300
learning rate = 1e-2
device = "cuda" if torch.cuda.is_available() else 'cpu'
eval_iters = 200
torch.manual_seed(1337)
# 1. read and explore the data
## 1. download tiny shakespeare dataset
!wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/inpu.txt
## 2. open the text file
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
## 3. print length of characters in text file and check the text
print("length of dataset in characters: ", len(text))
print(text[:1000])
## 4. dataset에서 unique한 word 확인하는 방법
chars = sorted(list(set(text))) # 전체 dataset에서 유일한 character들의 list
vocab_size = len(chars)
print(''.join(chars))
print(vocab_size) # 65
# 2. tokenization-raw string(character)을 sequence of integer로 바꾸기 위해서.
## 1. string을 token으로 바꾸어주는 것.
# create a mapping from characters to integers
stoi = {ch: i for i, ch in enumerate(chars)}
itos = {i: ch for i, ch in enumerate(chars)}
encode = lambda s: [stoi[c] for c in s] # encoder는 string을 받아서, 그 token(여기서는 한개의 character)에 해당하는 integer들의 list를 return한다.
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: integer의 list를 받아서, string을 출력한다.
print(encode("hii there"))
print(decode(endcode("hii there"))) # 를 하게 되면, list의 integer를, 다시 hi there로 바꾸어준다.
## 2. shakespeare의 모든 data를 tokenize하자.
import torch
data = torch.tensor(encode(text), dtype=torch.long) # 모든 text를 encoding해서, tensor에 넣겠다.
print(data.shape, data.dtype) # torch.Size([1115394]) torch.int64
print(data[:1000]) # 1000개의 sequence를 보자.
## 3. train/validation split을 하자. 9:1로. (overfitting을 막기 위해서, 즉 정확히 90%의 data처럼 결과가 나오지 않도록.)
n = int(0.9*len(data))
train_data = data[:n]
val_data = data[n:]
# 3. data loader -> batches of chunks of data
## 3. batch dimension을 맞춰야 한다.
torch.manual_seed(1337)
batch_size = 4 # 병렬적으로 돌릴 독립적인 8개의 글자
block_size = 8 # maximum context length (8개의 글자)
def get_batch(split):
data = train_data if split == 'train' else val_data # split이 training split이면 train_data를 볼 것이다.
ix = torch.randint(len(data) - block_size, (batch_size,) ) # batch_size(4) 개의, (0, 100000 - 8) 사이의 숫자 중에서, (4,) 처럼 data가 나오게 한다.
x = torch.stack([data[i: i+block_size] for i in ix]) # i 번째에서 시작하는 starting block
y = torch.stack([data[i+1 : i+block_size+1]for i in ix]) # x 다음 1개 이후에 나오는 8개의 character로 이루어진 sequence.
x,y = x.to(device), y.to(device)
return x, y # x, y는 4*8 tensor가 된다.
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X,Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
xb, yb = get_batch('train')
print('inputs:')
print(xb.shape) # torch.Size([4,8])
print(xb)
print('targets:')
print(yb.shape)
print(yb)
print('----')
for b in range(batch_size): # batch dimension
for t in range(block_size): # time dimension
context = xb[b, :t+1]
target = yb[b,t]
print(f"when input is {context.tolist()} the target: {target}")
# 4. baseline: bigram LM, loss, generation
## bigram pytorch model
torch.manual_seed(1337)
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size) # shape of row, col
def forward(self, idx, targets=None): # index, input x == idx
# idx and targets are both (B,T) tensor of integers
logits = self.token_embedding_table(idx) # (B,T,C) == (4,8,65) # 여기서 channel은 token을 몇차원의 벡터로 나타낼 것인지에 대해서, 그 벡터의 차원이 되는 것. 자세한 설명은 아래에.
if targets is None: # generate에서 self(idx)만 할 수 있게끔
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T,C) # CE API에 맞추기 위해서. C가 두번쨰 차원으로 나와야 하기 때문이다.
tartgets = targets.view(-1) # targets.view(B*T)와 같은 효과.
loss = F.cross_entropy(logits, targets) # loss는 prediction(logits)와 targets와의 CE다.
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B,T) array of indices in the current context
for _ in range(max_new_tokens):
# get the predictions
logits, loss = self(idx)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B,C)
# apply softmax to get probabilites
probs = F.softmax(logits, dim=-1) # (B,C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B,1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
model = BigramLanguageModel(vocab_size)
m = model.to(device)
logits, loss = m(xb, yb)
print(logits.shape)
print(loss)
idx = torch.zeros((1,1), dtype=torch.long) # zero는 newline character다. 그래서 sequence의 첫번째 character로 넣을 만 한 것 같다.
# 또 idx의 차원을 1,1로 함으로써, B가 1, T(train of tokens)가 1 차원이 된다. 이 말은, sequence가 1개고, 앞으로 token은 추가될 것인데, 결국 sequence가 1개라는 것은 문장이 한개라는 것이다.
print(decode(m.generate(idx, max_new_tokens=100)[0].tolist())) # generate는 batch에서 작용되기 때문에, 하나의 batch를 뽑아내야 한다. 이거는, indexes(tokens)의 list로 만들고, decode 함수로 character로 다시 바꾼다.
# 5. training the bigram model --> pytorch optimzer, train
# create a PyTorch optimizer
optimizer = torch.optim.adamW(m.parameters(), lr=learning_rate) # 작은 모델은 더 작아도 됨.
# xb, yb = get_batch('train')
# 'train' 이면 train data를 활용해서, batch_size 만큼의 batch차원을 가지고, block_size(8) 만큼의 train of data를 가진다. 즉 (batch_size, block_size)의 차원을 가진다. xb는, yb는 그 다음 8개의 character를 나타낸다. x가 'hi my na' 라면, y는 'i my nam'이 된다.
batch_size = 32
for iter in range(max_iters):
# sample a batch of data
if iter % eval_interval == 0:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = m(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
print(loss.item())
context = torch.zeros((1,1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=500)[0].tolist()))
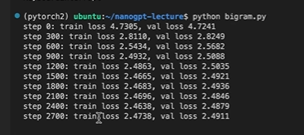 이렇게 뜨고,
이렇게 뜨고,
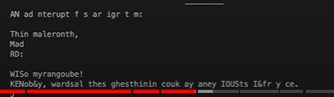 이런 sample이 출력된다.
이런 sample이 출력된다.
7-1. version1: averaging past context with for loops, the weakest form of aggregation
1. math trick in self-attention
# consider the following toy example:
torch.manual_seed(1337)
B,T,C = 4,8,2 # batch, time, channels
x = torch.randn(B,T,C)
x.shape
# We want x[b,t] = mean_{i<=t} x[b,i]
xbow = torch.zeros((B,T,C)) # 우선 bag of words를 B,T,C 차원으로 만든다.
for b in range(B): # batch에 대해서 iterate,
for t in range(T): # time에 대해서 iterate,
xprev = x[b,:t+1] # (t,C), 해당 batch에 대해서, t 까지의 timestep을 선택,
xbow[b,t] = torch.mean(xprev, 0) # xprev에 대해서, 첫번쨰 dimension(t)에 대해서, 평균을 내버린다. 그래서 C차원의 1차원 벡터를 얻을 것이다.
x[0]을 하면, 첫번째 batch
xbow[0]을 하면,
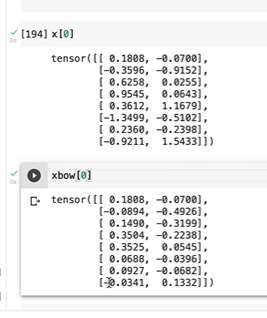 이런 결과가 나온다.
이런 결과가 나온다.
결국 평균을 하게 된다.
7-2. version2: 하삼각행렬을 통한 평균
2. 하삼각행렬을 만드는 방법
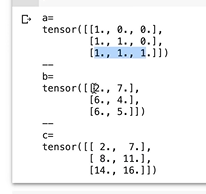
torch.tril(torch.ones(3,3))
# tensor([[1., 0., 0.],
# [1., 1., 0.],
# [1., 1., 1.]])
이거를 행렬의 왼쪽에 곱하게 되면, weighted sum이 된다. 오른쪾 행렬의 column을 그냥 다 sum하게 됨.
torch.manual_seed(42)
a = torch.tril(torch.ones(3,3))
b = torch.randint(0,10,(3,2)).float()
c = a @ b
# print ...
평균을 하려면,
torch.manual_seed(42)
a = torch.tril(torch.ones(3,3))
a = a / torch.sum(a,1,keepdim=True) # 열(dim=1)으로 다 합을 하면, n번째 행은 n이 되고, broadcasting되어서, 차원이 확장되어서, a에 대해서 elementwise division을 수행하게 되는 것.
b = torch.randint(0,10,(3,2)).float()
c = a @ b # (3,3) * (3,2)
# print ...
3. version2: 1번 코드 단순
이제 이거를 하삼각행렬을 통한 평균으로 코드를 간단화해보자.
# We want x[b,t] = mean_{i<=t} x[b,i]
xbow = torch.zeros((B,T,C)) # 우선 bag of words를 B,T,C 차원으로 만든다.
for b in range(B): # batch에 대해서 iterate,
for t in range(T): # time에 대해서 iterate,
xprev = x[b,:t+1] # (t,C), 해당 batch에 대해서, t 까지의 timestep을 선택,
xbow[b,t] = torch.mean(xprev, 0) # xprev에 대해서, 첫번쨰 dimension(t)에 대해서, 평균을 내버린다. 그래서 C차원의 1차원 벡터를 얻을 것이다.
wei = torch.tril(torch.ones(T,T))
wei = wei / wei.sum(1, keepdim=True)
wei
-1.png)
wei = torch.tril(torch.ones(T,T))
wei = wei / wei.sum(1, keepdim=True)
xbow2 = wei @ x # wei(T,T) @ (B,T,C) --> 브로드캐스팅 되어서, (B,T,T) @ (B,T,C) 연산을 수행하게 된다. x가 우리가 하삼각행렬을 통해서 평균? 연산을 수행하고 싶은 것.
torch.allclose(xbow, xbow2) # True, 두 행렬이 거의 비슷하다.
결국 weighted aggregation, weighted sum이다. 어떤 weight을 사용하냐면, wei 행렬을 이용해서 weighted sum을 하는 것이다.
7-3. version3: adding softmax
##
tril = torch.tril(torch.ones(T, T)) # masked_fill을 위한 tril 행렬 정의, (T,T) 모양을 가진 행렬을 하삼각행렬로 만들
wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf')) # tril 이 0인 부분은, tril 이라는 행렬에서, 0인 부분을, masking하기만 하면 된다.
-2.png)
tril = torch.tril(torch.ones(T, T)) # masked_fill을 위한 tril 행렬 정의, (T,T) 모양을 가진 행렬을 하삼각행렬로 만들
wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf')) # tril 이 0인 부분은, tril 이라는 행렬에서, 0인 부분을, '-inf' 로 대체한다.
wei = F.softmax(wei, dim=-1)
xbow3 = wei @ x
torch.allclose(xbow, xbow3)
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
##
댓글남기기