
Blog Full Notice
back to main page
LG_CBM paper summary
motivation: VLG_CBM paper summary
1. Introduction
CBM(Concept Bottleneck Model)은 중간에 Concept Bottleneck Layer(CBL)을 삽입해서, 사람이 이해할 수 있는 개념 단위로 예측 근거를 제공한다.
그러나 기존 CBM의 한계는, 중간 개념 레이어를 학습하려면 이미지마다 개념 레이블이 수작업으로 필요하다. 이 수작업은 비용이 많이 들고, 확장성이 낮다.
그래서, 몇몇 방법들은, LLM과 VLM을 활용한 자동화를 한다.
LLM: 개념 후보를 생성하고, VLM: 이미지와 텍스트를 정렬하여 지도.
이로써 CBM을 대규모 데이터셋(예: ImageNet) 에도 적용 가능해졌음.
그러나 아직 두가지 문제는 해결이 안되었음..
문제 1. 개념이 이미지와 맞지 않음 (비정합)
LLM이 생성한 개념은 때때로 이미지와 맞지 않거나, 시각적으로 관찰 불가능한 것들을 포함. loud music, location같은. 결론적으로 faithfulness(설명의 사실성)이 떨어진다.
문제 2. 정보 누수 (Information Leakage)
실험적으로 확인된 문제: 개념이 의도하지 않은 정보를 포함(encode)함
실험적으로 확인된 문제: 개념이 의도하지 않은 정보를 포함함
- 심지어 무작위 개념을 사용해도 높은 정확도를 얻을 수 있음
- 즉, 모델이 개념을 해석 가능한 정보가 아닌 단순 정보통로로 사용한다는 뜻
(Information Leakage: 참고 논문: 1. # Promises and Pitfalls of Black-Box Concept Learning Models, 2. # Do Concept Bottleneck Models Learn as Intended?)
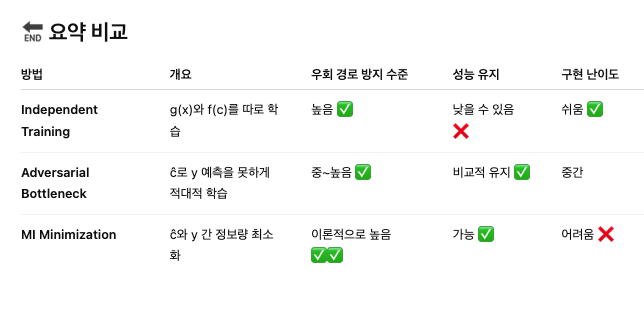
그래서 논문은 VLG-CBM을 제안하는데,
workshop paper at ICLR 2021
DO CONCEPT BOTTLENECK MODELS LEARN AS INTENDED?
Andrei Margeloiu et al,
bypass path: concept bottleneck layer가 원래 목적대로 “정보 병목” 역할을 하지 않고, 그저 feature representation을 위한 hidden layer처럼 작동하기 때문에,
모델이 원래 막혔어야 할 정보를 몰래 “우회해서” 통과시킨다
## ✅ 핵심 요약
- CBM의 concept layer는 원래 target 예측 정보를 **걸러내는 병목 역할**을 해야 해요
- 그런데 joint training 시에는 **그 병목을 우회해서** target 예측에 필요한 정보를 concept 안에 몰래 담는 경우가 많아요
- 그래서 그 layer는 더 이상 “bottleneck”이 아니고, **"우회 경로" (bypass path)** 역할을 하게 됩니다
---
원하시면, 이 우회 경로를 **어떻게 막을 수 있는지**(예: independent training, adversarial bottleneck, mutual information 제한 등)에 대해서도 설명드릴 수 있어요!
##### 나의 말:
independent training, adversarial bottleneck, mutual information 제한 등에 대해서 다 알려줘봐.
###### ChatGPT의 말:
좋아요. 이건 CBM(Concept Bottleneck Model)의 해석 가능성을 지키기 위해 매우 중요한 주제예요.
여기선 총 세 가지 전략을 중심으로 자세히 설명드릴게요:
---
## ✅ 개요: 왜 이런 전략들이 필요한가?
CBM에서 joint training을 하면 **concept layer가 target 정보를 우회 전달하는 통로**가 되기 때문에,
- **해석 가능성 (interpretability)**
- **개입 가능성 (intervenability)**
이 모두 깨집니다.
그래서 이를 막기 위해 여러 **훈련 전략 또는 구조적 제한**이 제안됩니다. 대표적으로:
### 🧱 1. Independent Training
### 🧨 2. Adversarial Bottleneck
### 🔗 3. Mutual Information Minimization
---
## 🧱 1. Independent Training
### 📌 정의
Concept predictor g(x)g(x)g(x)와 target predictor f(c)f(c)f(c)를 **완전히 독립적으로 학습**하는 방식입니다.
### 🔄 훈련 순서
1. g(x)g(x)g(x)를 학습
- Loss: Lc(g(x),c)\mathcal{L}_c(g(x), c)Lc(g(x),c)
- → 입력으로부터 **concept을 정확히 추정**하는 데 집중
2. f(c)f(c)f(c)를 학습
- Loss: Lt(f(c),y)\mathcal{L}_t(f(c), y)Lt(f(c),y)
- → concept이 주어졌을 때 target을 맞추는 mapping 학습
✅ 이때 fff는 **오로지 사람이 라벨링한 concept ccc** 에만 의존
→ concept layer에 target 정보가 몰래 들어갈 여지가 없음
→ **우회 경로 차단**
### 📉 단점
- 개념 예측이 부정확하면 target 예측 성능도 그대로 나빠짐
- 학습은 깔끔하지만 **예측 성능이 joint보다 낮은 경우 많음**
---
## 🧨 2. Adversarial Bottleneck
### 📌 핵심 아이디어
> **concept layer가 target 정보를 “몰래 담지 않도록” 강제로 막자.**
이를 위해 **adversary**(판별기)를 붙입니다.
→ concept vector c^=g(x)ĉ = g(x)c^=g(x)만 보고 target yyy를 맞추려는 "적대적 네트워크"를 추가하고,
**g(x)가 target 정보를 숨기지 못하도록 학습을 유도**합니다.
### 🔁 구조
- Main CBM:
x→g(x)=c^→f(c^)=yx \to g(x) = ĉ \to f(ĉ) = yx→g(x)=c^→f(c^)=y
- Adversary:
c^→D(c^)=y^advĉ \to D(ĉ) = \hat{y}_{adv}c^→D(c^)=y^adv
### 🎯 Loss 구성
1. Main CBM:
ming,fLtask(f(g(x)),y)+λ⋅Lconcept(g(x),c)\min_{g, f} \mathcal{L}_{task}(f(g(x)), y) + \lambda \cdot \mathcal{L}_{concept}(g(x), c)g,fminLtask(f(g(x)),y)+λ⋅Lconcept(g(x),c)
2. Adversary:
maxDLadv(D(g(x)),y)\max_{D} \mathcal{L}_{adv}(D(g(x)), y)DmaxLadv(D(g(x)),y)
3. 전체:
ming[Lconcept(g(x),c)−γ⋅Ladv(D(g(x)),y)]\min_{g} \left[ \mathcal{L}_{concept}(g(x), c) - \gamma \cdot \mathcal{L}_{adv}(D(g(x)), y) \right]gmin[Lconcept(g(x),c)−γ⋅Ladv(D(g(x)),y)]
→ g(x)는 concept은 잘 맞추되, **adversary가 target을 맞추지 못하도록** target 정보는 제거하게 유도됨
### ✅ 장점
- **우회 경로 억제 + 성능 유지 가능성**
- joint보다 더 신뢰할 수 있는 해석 가능성 제공
### ⚠️ 단점
- 학습 복잡도 증가
- adversarial training의 안정성 이슈
---
## 🔗 3. Mutual Information (MI) Minimization
### 📌 목표
> Concept vector c^ĉc^와 target yyy 사이의 **상호정보량(mutual information, MI)** 을 최소화하자.
이 전략은 다음과 같은 가정에서 출발합니다:
> “CBM의 concept layer는 target 정보를 직접 담아서는 안 된다.”
> → 그럼 I(c^;y)I(ĉ; y)I(c^;y)를 줄이면 우회 경로를 막을 수 있지 않을까?
### 🧮 Mutual Information이란?
- I(c^;y)I(ĉ; y)I(c^;y): concept과 target 사이에 **서로 알고 있는 정보량**
→ 크면, ĉ만 봐도 y를 알 수 있다는 뜻 (우회 가능성 ↑)
→ 작으면, y에 대한 정보가 거의 없음 (우회 가능성 ↓)
---
### 🔁 학습 방식
- Objective:
ming,fLtask(f(g(x)),y)+λ⋅Lconcept(g(x),c)+β⋅I(g(x);y)\min_{g, f} \mathcal{L}_{task}(f(g(x)), y) + \lambda \cdot \mathcal{L}_{concept}(g(x), c) + \beta \cdot I(g(x); y)g,fminLtask(f(g(x)),y)+λ⋅Lconcept(g(x),c)+β⋅I(g(x);y)
- 보통 I(c^;y)I(ĉ; y)I(c^;y)를 직접 계산하긴 어려우므로,
**MI estimator** (e.g., MINE) 또는 **variational bounds** 등을 사용해 근사적으로 최소화
### ✅ 장점
- 정량적으로 concept vector에서 target 정보를 뽑아내지 못하게 함
- 보다 **이론적으로 타당한 정보 제어 가능**
### ⚠️ 단점
- MI 추정이 어렵고 부정확할 수 있음
- 계산량이 큼
https://openreview.net/forum?id=2xRTdzmQ6C&utm_source=chatgpt.com CBM에서 Variational Information bottleneck(VIB, VAE optimization을 classification에서 하는 것)이미 나와있었음. ICLR 2025 reject.
2. Related work.
1. Concept Bottleneck Models (CBM)의 역사
가장 초기 CBM은 Autoencoder 기반. 데이터를 저차원 ‘해석 가능한’ basis concept로 표현하려는 시도.
CBM의 정립 (Koh et al., 2020 [6]) 개념 = 사람이 직접 정의한 중간 속성 모델 구조는 다음과 같은 3단계: 이미지 → Feature (ϕ) → Concept Layer (g) → Final Layer (h) → 클래스 예측
즉, 개념을 먼저 예측하고 → 개념을 기반으로 최종 클래스 결정.
📌 주요 수식 구조 Feature 추출: z = ϕ(x) 개념 예측: c = g(z) = W_c z 클래스 예측: ŷ = h(c) = W_F g(z) + b_F
2. 최근 접근들: 자동화된 CBM 훈련
기존 CBM의 한계는: 개념 라벨을 사람이 일일이 달아야 함 → 비효율적이고 확장 불가능
그래서 등장:
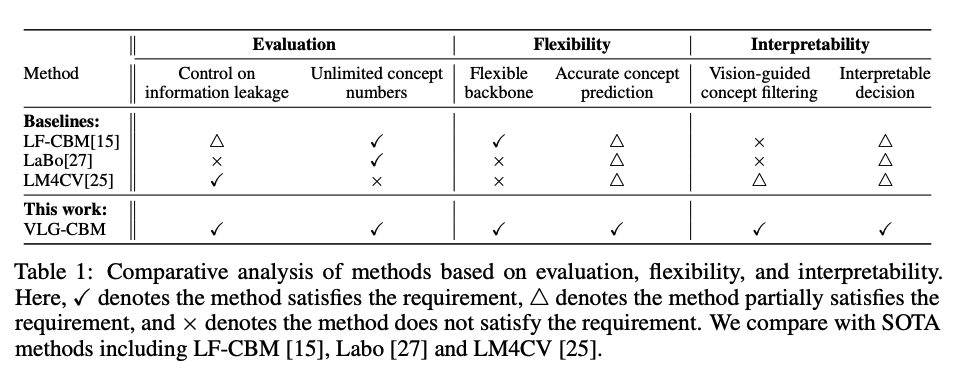
LF-CBM (Oikarinen et al. [15])
- LLM을 사용해서 개념 후보를 생성하고,
- CLIP의 텍스트 임베딩을 사용해 개념을 정렬
- 최종적으로 sparse linear layer로 클래스 예측
- 단점: CLIP space와 직접 정렬만 하다 보니 비시각적 개념 포함됨
LM4CV (Kim et al. [25])
- task-specific 개념을 자동으로 찾음
- CLIP 텍스트 임베딩 space에서 Nearest Neighbor 검색으로 개념-텍스트 매핑
단점: 개념 수 적고, Dense Layer 사용 → 해석 불가능 VLG-CBM 실험에서 랜덤 baseline보다도 성능 낮음
LaBo (Yang et al. [27])
- 개념 수 줄이기 위해 서브모듈 최적화 (submodular optimization) 사용
- 개념을 CLIP backbone 기반으로 학습 단점: CLIP backbone에만 의존함 NEC 조절이 불가능, 해석성 낮음
-
Pham et al. [16] OWL-ViT 기반 open-vocabulary detector를 이용해 설명을 제공 하지만 사전 훈련 모델 자체를 수정해야 하며, 기존 백본에 CBL을 삽입할 수 없음 반면 VLG-CBM은 post-hoc으로 어디든 삽입 가능
-
Sun et al. [20] 정보 누수를 실험적으로 측정 → Top-k 개념 제거 후 정확도 감소 관찰 하지만 개념 수(k)에 따른 정량화 없음 VLG-CBM은 이를 보완하기 위해 NEC 메트릭 제안
-
Roth et al. [17] 무작위 단어도 CLIP에서 꽤 정확한 성능을 낼 수 있다는 실험 수행 VLG-CBM의 정보 누수 이론과 실험을 이 결과와 연결
3. method
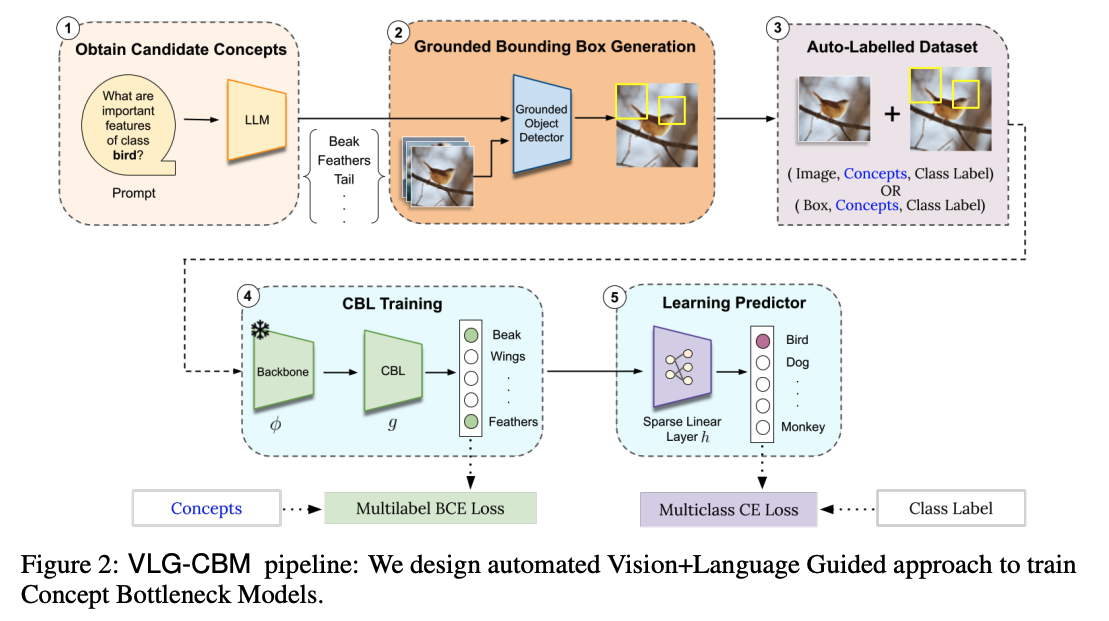
3.1 Automated Generation of Auxiliary Dataset
VLG-CBM의 핵심 아이디어 중 하나 🎯 목표: 사람 없이도 개념 라벨이 달린 데이터셋을 자동으로 만드는 방법
전체 흐름 요약
- LLM을 통해 후보 개념 생성 (S)
- Open-vocabulary Object Detector (Grounding-DINO) 를 통해 → 개념이 실제 이미지에서 시각적으로 관측 가능한지 검사
- Bounding box 기반으로 개념을 필터링 + 이미지-개념 매핑
- 각 이미지에 대해 개념 벡터 oᵢ를 생성 → D′라는 새로운 개념 라벨 데이터셋 구성




3.2 Training Concept Bottleneck Layer
🎯 목표
이미지 속에 어떤 개념들이 있는지를 예측하는 함수
g(x)(즉, CBL)를 학습한다.

그리고 sequential하게 학습함.


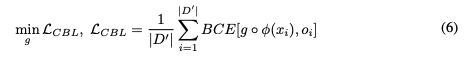
3.3 Mapping Concept to Classes

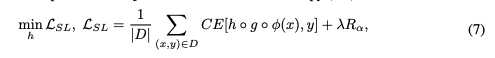


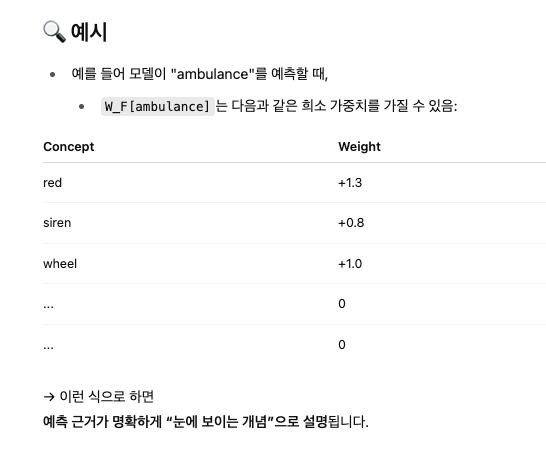
4. Unifying CBM evaluation with Number of Effective Concepts (NEC)
🧠 문제의식: CBM 정확도만으로 평가해도 될까?
⚠️ 기존 평가 방식
- 보통 CBM의 성능은 최종 분류 정확도(Accuracy) 만으로 평가됨
- 하지만 이건 큰 문제가 있음
- 개념이 의미 없는 정보라도 정확도는 올라갈 수 있음
- → 예: 랜덤한 개념을 써도 성능이 높게 나옴 (정보 누수!)
📌 정확도가 높다고 해석 가능한 CBM이라 할 수는 없음
🚨 4.1 Theoretical Analysis: Random CBL도 성능이 좋을 수 있다?
논문은 다음과 같은 이론적 결과(Theorem 4.1) 를 제시합니다:
“CBL이 전혀 학습되지 않은 랜덤 행렬이어도,
개념 수 k만 충분히 많으면 어떤 선형 분류기도 근사 가능하다.”
📐 수식 정리
- z ∈ ℝᵈ: 백본 임베딩
- g(z) = W_c z ∈ ℝᵏ: 랜덤한 개념 벡터 (W_c ~ N(0,1))
- h(g(z)) = W_F g(z): 클래스 예측
주요 결과:
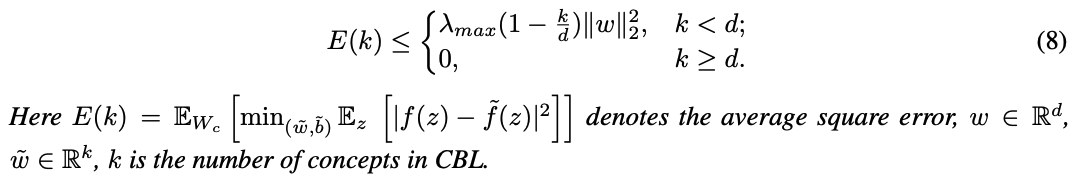
E(k): 원래 모델 f(z)와 CBM 모델 ˜f(g(z))의 예측 차이 제곱 오차λ_max: z의 분산 행렬의 최대 고유값- k가 커지면 → 오차가 줄어듦 → 결국 정확도 높아짐
📌 의미
- 개념 수 k가 많으면 많을수록 → 랜덤한 CBL도 정확도 높게 나올 수 있음
- 그래서 기존 CBM들은 실제로 해석 가능한 개념을 쓰는지 확신할 수 없음
✅ 4.2 제안: Number of Effective Concepts (NEC)
🎯 목적:
CBM을 평가할 때 ‘정확도’만 보지 말고,
모델이 실제로 몇 개의 개념에 의존했는지도 함께 보자.
🔢 NEC 정의
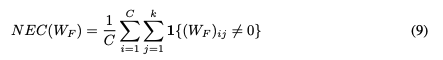
W_F ∈ ℝ^{C × K}: 클래스 예측용 선형 계층C: 클래스 수K: 개념 수- → 클래스당 평균적으로 몇 개의 개념을 사용하는가?
📌 NEC가 왜 중요한가?
✔️ 1. 정보 누수 제어
- NEC가 클수록 → 더 많은 개념 사용 → 정보 누수 가능성 커짐
- NEC를 작게 제한하면 → 무작위 CBL 성능 급감 → 정보 누수 방지
✔️ 2. 해석 가능성 확보
- 사람이 한 번에 볼 수 있는 개념 수는 제한적임 (예: 5~10개)
- NEC가 작을수록 → 결정 이유가 간결하고 명확함
✔️ 3. 공정한 비교 가능
- 기존 CBM들 간 비교가 어려운 이유:
- 어떤 건 100개 개념, 어떤 건 10개 개념 사용
- 어떤 건 dense, 어떤 건 sparse
- NEC는 개념 수와 sparsity를 모두 반영한 통합 평가 지표
🎯 평가 지표로 제안된 것들
| 지표 | 설명 |
|---|---|
| ANEC-5 | NEC=5일 때 모델의 정확도 |
| ANEC-avg | NEC ∈ {5,10,15,20,25,30} 범위에서 평균 정확도 |
→ 이 지표들은 해석 가능한 범위 내에서 CBM이 얼마나 잘 작동하는지를 측정합니다.
📊 실험 결과 예시 (Fig. 3, Section 5 참고)
- NEC가 클 때는 랜덤 CBL도 성능 높음
- NEC가 작아질수록 → 기존 방법 (LF-CBM 등) 성능 급감
- 하지만 VLG-CBM은 NEC=5에서도 성능 유지
✅ 핵심 요약
| 항목 | 설명 |
|---|---|
| 기존 문제 | CBM이 실제로 ‘개념’을 쓰고 있는지 확신할 수 없음 |
| 이론적 결과 | 랜덤 개념도 정확도 높게 만들 수 있음 (Theorem 4.1) |
| NEC란? | 클래스당 사용된 개념 수의 평균 |
| 왜 중요한가? | 정보 누수 방지, 해석 가능성 확보, 공정한 비교 가능 |
| 평가 방식 | ANEC-5, ANEC-avg → NEC를 고정한 상태에서 성능 평가 |
5. Experiments
📌 실험 목적
- VLG-CBM의 정확도 성능 평가
- 개념 예측의 신뢰성 (faithfulness) 검증
- 모델 해석 가능성 (interpretability) 정성적 분석
- 정보 누수 방지 효과 확인 (via NEC 제어)
백본 (Backbone)
- CLIP-RN50 (CLIP 기반)
- ResNet-18 / ResNet-50 (non-CLIP)
- CUB → ResNet-18
- ImageNet/Places365 → ResNet-50
→ 이를 통해 CLIP에 종속되지 않는 일반성도 테스트
📊 평가 지표
🎯 Accuracy under NEC
- ANEC-5:
- NEC = 5일 때 정확도
- (사람이 해석 가능할 수준의 개념 수 제한)
- ANEC-avg:
- NEC ∈ {5,10,15,20,25,30} 평균 정확도
- 해석 가능성과 성능의 트레이드오프 평가
🔧 NEC 제어 방법
-
LF-CBM / VLG-CBM:
→ ElasticNet + GLM-SAGA로 sparsity 조절 - LM4CV:
→ dense layer 사용 → 개념 수 자체를 제한해서 NEC 조절 - LaBo:
→ 원래는 NEC 제어 못함 → VLG 방식으로 sparse layer 재적용
댓글남기기